
TS. Nguyễn Thanh Huyền
Trường Đại học Lao động – Xã hội
(Quanlynhanuoc.vn) – Bài viết đánh giá các công cụ, kỹ thuật phân tích giá trị chính xác (Value Analysis) trong phân tích tĩnh chương trình và đề xuất một bộ chuẩn tham chiếu nhằm đánh giá độ chính xác (precision) của các công cụ phân tích giá trị, so sánh hiệu năng (performance), hỗ trợ cộng đồng nghiên cứu phát triển thuật toán tốt hơn. Hiện tại, lĩnh vực này thiếu một bộ chuẩn đánh giá toàn diện có dữ liệu chuẩn đúng, rõ ràng. Do đó, ValBench được xây dựng để giải quyết vấn đề này.
Từ khóa: Phân tích giá trị; kiểm thử phần mềm; đánh giá độ chính xác kiểm thử thủ công; so sánh hiệu năng.
1. Đặt vấn đề
Phân tích giá trị là một trong những viên gạch quan trọng trong phân tích tĩnh. Tầm quan trọng của phân tích giá trị rất lớn, thể hiện qua việc hỗ trợ phân tích luồng chương trình, giúp xác định duy nhất hàm được gọi trong lớp và hàm mục tiêu, từ đó tránh bỏ sót hoặc nhầm lẫn. Hơn nữa, giúp mô hình hóa tương tác giữa các thành phần, cho phép hiểu cách các thành phần trao đổi dữ liệu và ngăn việc trộn lẫn thông tin giữa các đối tượng hoặc thông điệp. Ngoài ra, phân tích giá trị còn có vai trò chủ chốt trong việc phát hiện lỗ hổng bảo mật, giúp kiểm tra các giá trị tham số quan trọng, qua đó phát hiện các lỗi, như: dùng thuật toán lỗi thời, gửi dữ liệu nhạy cảm không an toàn hoặc khóa cứng. Bảo đảm tính đầy đủ và chính xác trong phân tích tĩnh, một yếu tố then chốt cho độ tin cậy của các công cụ phân tích.
Hầu hết các nghiên cứu phân tích giá trị đều tập trung vào phân tích chuỗi. Một số phương pháp được phát triển nhằm trả về chuỗi cụ thể, trong khi những phương pháp khác, như: JSA, Coal hoặc Violist trả về biểu thức chính quy. Phương pháp thứ hai với việc trả về biểu thức chính quy, có thể hỗ trợ hiệu quả các giá trị phụ thuộc vào các đầu vào bên ngoài không khả dụng cho phân tích tĩnh, ví dụ: đầu vào của người dùng hoặc kết quả được truy xuất từ máy chủ từ xa thông qua kết nối mạng.
Bất chấp các nghiên cứu phân tích giá trị hiện có, việc đo lường độ chính xác của phân tích giá trị vẫn không hề đơn giản. Nó đòi hỏi một tập dữ liệu toàn diện với một sự thật cơ bản đã biết. Mặc dù các ứng dụng thực tế có thể cung cấp các ví dụ phức tạp nhưng chúng thường thiếu sự thật cơ bản. Việc thiết kế ngược các ví dụ này đòi hỏi một nỗ lực trên quy mô lớn. Do đó, các ví dụ thực tế rất hữu ích cho việc phân tích thời gian và mức tiêu thụ bộ nhớ của phân tích giá trị, nhưng không giúp đánh giá được độ chính xác.
2.1. Phân tích giá trị chính xác (Exact Value Analysis – EVA)
Phân tích giá trị chính xác là một hướng tiếp cận trong phân tích chương trình với mục tiêu suy luận chính xác giá trị của các biến tại từng điểm trong chương trình. Khác với các kỹ thuật phân tích truyền thống như diễn giải trừu tượng (abstract interpretation) hay phân tích luồng dữ liệu (data-flow analysis) thường dựa trên các miền giá trị trừu tượng (abstract domains) để bảo đảm tính khả thi, EVA hướng đến việc xác định tập giá trị đúng (ground truth) mà chương trình có thể sinh ra trên từng đường đi thực thi. Do vậy, EVA có thể được xem như chuẩn tham chiếu để đánh giá độ chính xác của nhiều kỹ thuật phân tích khác.
2.2 Phân tích tĩnh (Static Analysis)
Phân tích tĩnh là kỹ thuật phân tích mã nguồn mà không cần chạy chương trình nhằm suy luận các thuộc tính của chương trình. Mục tiêu là phát hiện lỗi, dự đoán hành vi hoặc bảo đảm một số tính chất an toàn trước khi chương trình thực thi.
Concrete values là giá trị cụ thể, xác định duy nhất của một biểu thức hoặc biến trong chương trình khi thực thi thực tế. Chúng là kết quả thực sự mà chương trình tạo ra với một bộ input cụ thể.
Regular expressions (regex) là một cách biểu diễn một tập (thường vô hạn) các chuỗi ký tự trong ngôn ngữ hình thức. Regex không biểu diễn một giá trị duy nhất mà biểu diễn một tập các chuỗi thoả mãn mẫu (pattern).
2.3. Ứng dụng trong xây dựng Callgraph
Trong các ngôn ngữ hỗ trợ dynamic dispatch, reflection hoặc lời gọi gián tiếp (indirect call), việc xây dựng Callgraph phụ thuộc mạnh vào khả năng suy luận các giá trị có thể của biến mang thông tin tên lớp hoặc con trỏ hàm.
Concrete values chỉ phản ánh duy nhất hàm được gọi trong một lần chạy dẫn đến việc bỏ sót các nhánh khả dĩ khác. Trong khi đó, regular expressions hoặc các miền trừu tượng (abstract domains) tương đương (như automata-based string domains) có thể biểu diễn tập tất cả chuỗi đại diện cho tên lớp hoặc tên hàm có thể xuất hiện. Nhờ đó, Callgraph được xây dựng đầy đủ và trung thực hơn. Đây là một bước thiết yếu trong nhiều pipeline phân tích, bao gồm phân tích luồng dữ liệu, phân tích rủi ro hay tối ưu hóa mã.
2.4. Ứng dụng trong phân tích Android ICC
Cơ chế ICC của Android cho phép các Activity, Service, BroadcastReceiver giao tiếp với nhau thông qua Intent. Các Intent này thường được xây dựng từ chuỗi động, ghép nối nhiều giá trị khác nhau. Concrete values không thể cung cấp cái nhìn toàn diện về mọi action, category hay URI mà Intent có thể chứa. Khi chỉ dựa trên các concrete values, phân tích tĩnh sẽ bỏ sót nhiều đường truyền liên thành phần, gây giảm độ bao phủ ICC graph. Ngược lại, regular expressions cho phép mô hình hóa toàn bộ các biến thể chuỗi action hoặc URI có thể xuất hiện, dù số lượng thực tế là vô hạn. Nhờ vậy, các công cụ phân tích có thể phát hiện nhiều lỗ hổng ICC hơn như Intent hijacking, data leakage hay privilege escalation.
2.5. Diễn giải trừu tượng
Diễn giải trừu tượng là một khuôn khổ lý thuyết được đề xuất bởi Patrick Cousot và Radhia Cousot (1977) nhằm mô tả và phân tích hành vi của chương trình theo cách xấp xỉ nhưng có bảo đảm về mặt hình thức. Mục tiêu của AI là cho phép xây dựng các công cụ phân tích tĩnh sound (không bỏ sót lỗi khả dĩ), đồng thời, có thể chạy trong thời gian hữu hạn. Abstract Interpretation được xem là nền tảng quan trọng nhất cho static program analysis hiện đại vì nó thống nhất nhiều kỹ thuật, như: data-flow analysis, type systems, model checking và symbolic execution.
2.6. Thực thi tượng trưng và giải quyết ràng buộc
Symbolic Execution là một kỹ thuật phân tích tĩnh bán tự động, trong đó, chương trình được thực thi không phải trên các giá trị cụ thể (concrete values) mà bằng các ký hiệu (symbolic values). Mỗi biến đầu vào được gán một biểu tượng trừu tượng và quá trình thực thi sẽ lan truyền các biểu tượng này qua các câu lệnh, tạo thành các biểu thức đại số biểu diễn trạng thái chương trình tại từng điểm. Thay vì thu được một tuyến thực thi duy nhất, kỹ thuật này sinh ra một tập các đường đi khả dĩ (feasible paths), mỗi đường đi gắn với điều kiện rẽ nhánh tương ứng, gọi là path constraints.
2.7. Benchmarking trong phân tích chương trình
Benchmarking đóng vai trò trung tâm trong việc đánh giá và so sánh hiệu quả của các kỹ thuật phân tích chương trình. Khác với các lĩnh vực khác, phân tích chương trình đòi hỏi không chỉ đo lường hiệu năng thuần túy (như thời gian chạy hay mức sử dụng bộ nhớ) mà còn phải đánh giá chất lượng của kết quả phân tích trong bối cảnh vốn có sự đánh đổi giữa tính chính xác và tính khả thi. Do đó, một bộ benchmark tốt phải cho phép nhận diện đầy đủ các khía cạnh quan trọng của một phương pháp phân tích, từ mức độ bao phủ, tính ổn định, khả năng mở rộng cho đến mức độ chính xác của các kết quả thu được.
2.8. Các thước đo: Precision – Coverage – Performance
Để đánh giá một cách toàn diện hiệu quả của các kỹ thuật phân tích chương trình, việc sử dụng các thước đo định lượng là điều không thể thiếu. Trong số đó, ba thước đo quan trọng và phổ biến nhất là Precision (độ chính xác), Coverage (mức độ bao phủ) và Performance (hiệu năng). Ba thước đo này phản ánh các khía cạnh cốt lõi của bất kỳ hệ thống phân tích nào và thường được sử dụng như những trụ cột cơ bản trong việc so sánh và đánh giá các công cụ khác nhau.
3. Tổng quan các công cụ phân tích
3.1. Regex-based tools
Regex-based tools là các công cụ sử dụng Regular Expressions (biểu thức chính quy) để thực hiện các tác vụ xử lý văn bản, như: tìm kiếm, khớp mẫu, thay thế hoặc trích xuất dữ liệu. Regex là một chuỗi ký tự đặc biệt định nghĩa một mẫu tìm kiếm, ví dụ như: \d{3}-\d{3}-\d{4} để khớp với số điện thoại dạng 123 – 456 – 7890. Các công cụ này rất đa dạng, từ text editors, như: Visual Studio Code, Sublime Text, command-line tools, như: grep, sed, awk trên Linux/Unix đến các thư viện tích hợp trong ngôn ngữ lập trình, như: Python (re module), JavaScript, Java. Ngoài ra, còn có các online regex testers như Regex101.com giúp test và debug patterns.
3.2. JSA (automata)
JSA là một công cụ phân tích tĩnh được phát triển bởi nhóm nghiên cứu BRICS tại Đại học Aarhus, Đan Mạch. Công cụ này được thiết kế để thực hiện phân tích tĩnh các chương trình Java nhằm xác định những giá trị nào có thể xuất hiện như là kết quả của các biểu thức chuỗi. JSA hoạt động bằng cách sử dụng automata theory để xây dựng đồ thị luồng từ các tệp lớp và sinh ra một văn phạm phi ngữ cảnh với một ký hiệu không kết thúc cho mỗi biểu thức chuỗi. Sau đó, văn phạm này được biến đổi thành văn phạm đệ quy trái – phải hỗn hợp sử dụng biến thể của thuật toán Mohri-Nederhof và cuối cùng được biểu diễn dưới dạng automata đa tầng.
Điểm mạnh của JSA là khả năng kiểm tra tĩnh cú pháp của các biểu thức được sinh động, chẳng hạn như các truy vấn SQL, từ đó phát hiện các lỗi tiềm ẩn như tấn công chèn SQL, tấn công xuyên trang hoặc định dạng chuỗi không hợp lệ.
3.3. Concrete value tools
Concrete value tools là các công cụ phân tích chương trình dựa trên việc sử dụng các giá trị cụ thể (concrete values) thay vì các biểu diễn trừu tượng để kiểm tra và phát hiện lỗi trong code. Khác với regex-based tools sử dụng phân tích tĩnh và xấp xỉ bằng biểu thức chính quy, concrete value tools thực thi chương trình với các đầu vào thực tế để quan sát hành vi cụ thể.
Ví dụ: String query = “SELECT * FROM users WHERE id=” + userId
(1) Regex-based tool (như JSA): phân tích và xác định query có thể chứa pattern SELECT * FROM users WHERE id=<số nguyên>, bao phủ tất cả trường hợp có thể nhưng có thể sinh ra false positives.
(2) Concrete value tool: thực thi với giá trị cụ thể userId = 123 và quan sát kết quả thực tế “SELECT * FROM users WHERE id=123”, chính xác tuyệt đối nhưng chỉ kiểm tra được trường hợp đã test.
3.4. Harvester (hybrid)
Harvester là một công cụ phân tích hybrid (lai ghép) được phát triển bởi nhóm nghiên cứu Secure Software Engineering Group tại Technische Universität Darmstadt và Fraunhofer SIT, Đức. Công cụ này kết hợp giữa phân tích tĩnh (static analysis) và phân tích động (dynamic analysis) để trích xuất các giá trị runtime từ ứng dụng Android, đặc biệt là các ứng dụng có sử dụng kỹ thuật chống phân tích (anti-analysis techniques) như obfuscation, mã hóa chuỗi và phát hiện môi trường giả lập.
3.5. StringHound (deobfuscation)
StringHound là một công cụ giải mã chuỗi mã nguồn mở được phát triển bởi nhóm nghiên cứu tại Technical University of Darmstadt, Đức. Công cụ này được thiết kế để tự động nhận diện các chuỗi bị làm rối (obfuscated strings) và khôi phục lại dạng văn bản gốc của chúng trong các ứng dụng Java và Android. StringHound hoạt động theo quy trình năm bước: chuyển đổi Dalvik bytecode sang Java bytecode, nhận diện chuỗi bị làm rối và phương thức giải mã, xác định slicing criterion, thực hiện slicing có mục tiêu và cuối cùng thực thi slice để thu được chuỗi gốc. Công cụ sử dụng hai bộ phân loại bổ trợ: String Classifier dựa trên cây quyết định (decision trees) với 49 đặc trưng để nhận diện chuỗi bị làm rối và Method Classifier sử dụng tương quan Spearman để nhận diện các phương thức giải mã.
Thời gian xử lý trung bình: 2 – 3 phút mỗi ứng dụng với thời gian xây dựng và thực thi một slice đơn dưới 250ms.
3.6. ValDroid (static simulation)
ValDroid là một công cụ phân tích tĩnh được thiết kế để trích xuất các giá trị biến phức tạp từ các ứng dụng Android, đặc biệt hiệu quả trong việc xử lý mã bị obfuscate và chứa vòng lặp. Khác với các phương pháp unroll vòng lặp truyền thống hoặc sử dụng widening để tạo biểu thức chính quy, ValDroid thực thi vòng lặp với ngữ nghĩa chính xác của chương trình gốc, đánh giá điều kiện vòng lặp để xác định thời điểm kết thúc.
Kiến trúc hoạt động của ValDroid gồm hai pha chính: Slicing xác định các câu lệnh đóng góp vào giá trị cần tìm, chuyển đổi chúng thành các hàm toán học (transformers). Simulation áp dụng các transformers theo thứ tự để tính toán giá trị cuối cùng từ trạng thái ban đầu.
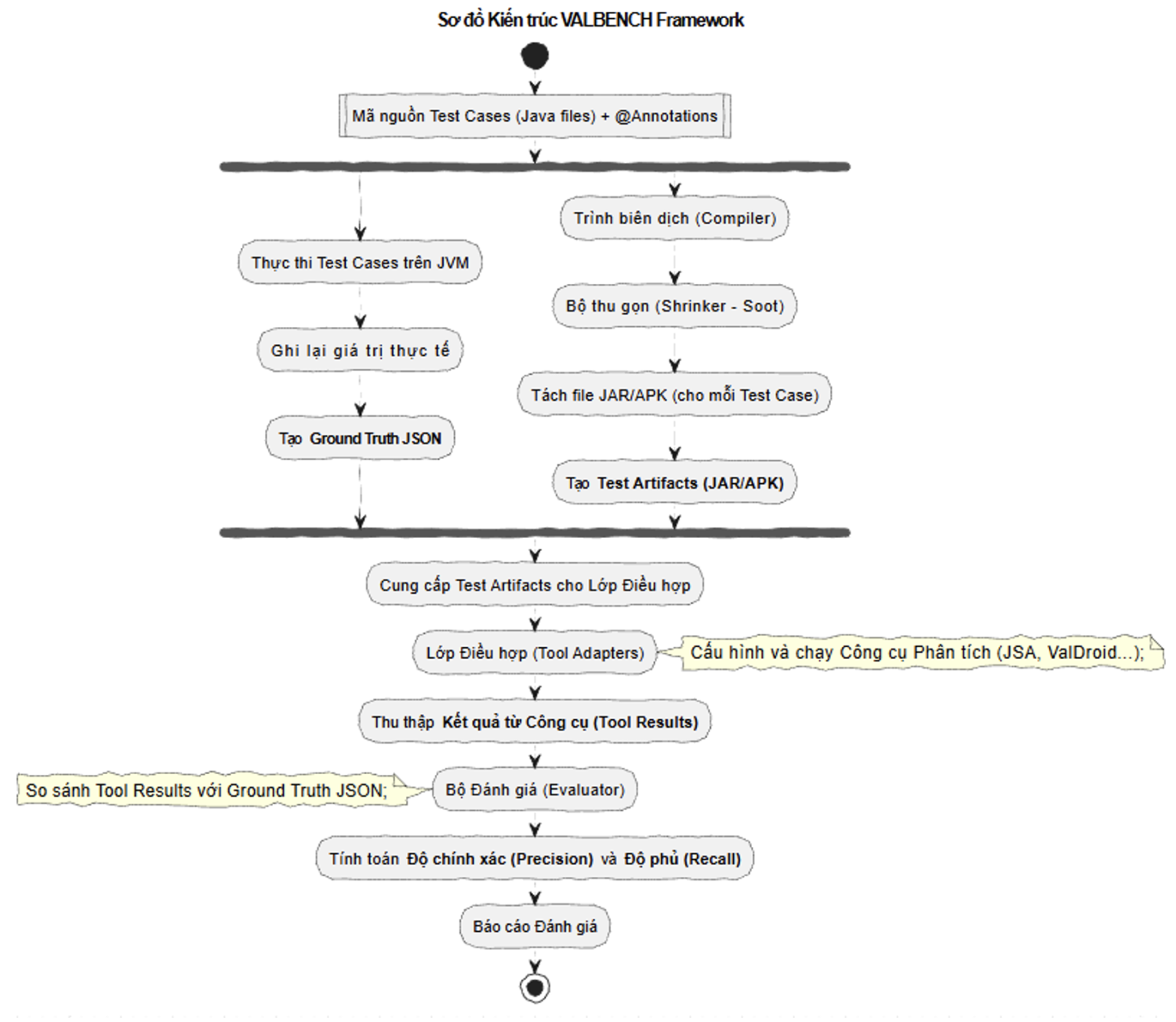
Mô tả quy trình theo Sơ đồ:
Đầu vào và song song hóa (Forking). Quá trình bắt đầu với Mã nguồn Test Cases (các tệp Java có chứa @Annotations). Từ mã nguồn, quy trình được phân nhánh (fork) thành hai luồng song song: Luồng 1. Tạo Ground Truth, tập trung vào việc tạo ra dữ liệu chuẩn đúng. Luồng 2. Xây dựng Artifact tập trung vào việc chuẩn bị các tệp nhị phân để công cụ phân tích có thể đọc.
Bộ tạo Ground Truth (Luồng 1): thực thi Test Cases trên JVM, các tệp mã nguồn được biên dịch và chạy thực tế trên máy ảo Java để tính toán giá trị. Ghi lại và xuất JSON, theo đó giá trị thực tế tại các điểm đánh dấu (annotations) được ghi lại và lưu trữ trong tệp Ground Truth JSON.
Bộ xây dựng Artifact (Luồng 2): biên dịch và thu gọn (Shrinker), mã nguồn được trình biên dịch xử lý, sau đó đi qua bộ thu gọn (Shrinker, dựa trên Soot) để tách nhỏ các test case thành các gói riêng biệt. Tạo Test Artifacts: đầu ra là các tệp JAR/APK đã được tối ưu, sẵn sàng cho việc phân tích.
Kết nối công cụ: hai luồng trên hội tụ lại, Test Artifacts (JAR/APK) được cung cấp cho bước tiếp theo. Lớp điều hợp (Tool Adapters) hoạt động như một giao diện, nhận Artifacts, khởi chạy các công cụ phân tích (như JSA, Harvester) và thu thập kết quả từ công cụ (Tool Results).
Bộ Đánh giá (Evaluator): bộ đánh giá nhận hai đầu vào chính, Ground Truth JSON (giá trị đúng) và Tool Results (giá trị dự đoán). Thành phần này thực hiện so sánh chuỗi nghiêm ngặt và tính toán các chỉ số đánh giá tiêu chuẩn, độ chính xác (Precision) và độ phủ (Recall).
Kết thúc là báo cáo đánh giá tổng hợp hiệu năng của các công cụ phân tích. Quy trình hoạt động của Valbench được thiết kế để giảm thiểu sự can thiệp thủ công và loại bỏ các sai sót do con người tạo ra. Quy trình bao gồm 5 bước chính. Mỗi trường hợp kiểm thử (test case) trong Valbench được viết bằng ngôn ngữ Java và đánh dấu bằng các chú thích, đặc biệt để framework có thể nhận diện. Cấu trúc Test Case, phương thức đầu vào (entry point) của mỗi bài test được chú thích bằng @ValueComputationTestCase. Một test case không giới hạn trong một phương thức mà có thể gọi sang các phương thức khác.
Hai loại Test Case chính: (1) Return-based (dựa trên giá trị trả về), công cụ phân tích cần tái tạo lại giá trị được trả về bởi phương thức. (2) Explicit Logging (Ghi nhật ký rõ ràng) đối với các phương thức void, test case sẽ gọi explicitLoggingPoint (Object) để chỉ định biến cần phân tích. Thực tế, framework sẽ tự động chèn các điểm logging này trước mỗi câu lệnh return để chuẩn hóa đầu vào cho các công cụ.
Một trong những đóng góp quan trọng nhất của Valbench là khả năng tự động tạo dữ liệu gốc đúng (ground truth), thay vì dựa vào việc gán nhãn thủ công dễ sai sót. Cơ chế thực thi, Framework biên dịch mã nguồn test case và thực thi trực tiếp trên máy ảo Java (JVM). Ghi nhận giá trị, trong quá trình chạy, mọi giá trị trả về hoặc giá trị tại các điểm explicitLoggingPoint sẽ được ghi lại và lưu trữ vào một tệp JSON.
Ưu điểm của phương pháp này bảo đảm tính chính xác tuyệt đối của dữ liệu gốc (correctness) và loại bỏ công sức lao động thủ công. Đối với các trường hợp không thể chạy trên JVM (ví dụ: logic đặc thù Android), tác giả có thể cung cấp giá trị mong đợi thông qua thuộc tính expectedValues trong annotation. Hầu hết các công cụ phân tích giá trị làm việc trên mã nhị phân (binary) thay vì mã nguồn. Do đó, Valbench tích hợp quy trình xây dựng tự động.
Tạo Artifact, Framework tự động đóng gói các test case thành tệp JAR (cho Java) và APK (cho Android). Trong quá trình thử nghiệm, tác giả phát hiện một số công cụ bị treo (timeout) khi phải xử lý một file JAR/APK chứa toàn bộ bộ test.
Giải pháp – Shrinker: Valbench tích hợp một tiện ích “Shrinker” dựa trên Soot. Tiện ích này tách và tạo ra các file JAR/APK nhỏ, mỗi file chỉ chứa một test case duy nhất cùng các thư viện tối thiểu cần thiết. Điều này đảm bảo tính công bằng và khả năng thực thi cho các công cụ yếu hơn. Để hỗ trợ đa dạng các công cụ phân tích với các giao diện khác nhau, Valbench sử dụng mẫu thiết kế Adapter.
Tool-specific Adapter: mỗi công cụ phân tích (ví dụ: JSA, Coal, ValDroid) kết nối với framework thông qua một lớp Adapter riêng.
Nhiệm vụ của Adapter: Adapter chịu trách nhiệm cấu hình công cụ, thực thi công cụ (qua dòng lệnh hoặc API), và thu thập kết quả đầu ra. Điều này giúp Valbench dễ dàng mở rộng để hỗ trợ các phương pháp mới trong tương lai.
Bước cuối cùng là so sánh kết quả thu được từ các Adapter với Ground Truth đã tạo ở bước 4.2.2.
Cơ chế so sánh chuỗi (string equality) giữa giá trị dự đoán và giá trị thực.
Xử lý biểu thức chính quy (Regex) với các công cụ trả về biểu thức chính quy thay vì giá trị cụ thể (như JSA), framework sẽ phân tách biểu thức (ví dụ: A|B) thành các phần cụ thể (A và B) để so sánh với ground truth. Bất kỳ biểu thức nào rộng hơn giá trị thực đều được coi là xấp xỉ quá mức (over-approximation).
Chỉ số đánh giá: Precision (độ chính xác), Recall (độ phủ). Trước khi Valbench ra đời, bộ test suite của JSA thường được sử dụng làm chuẩn nhưng nó tồn tại nhiều bất cập khiến việc đánh giá thiếu toàn diện.
Bảng IV-1 tóm tắt sự khác biệt cơ bản giữa Valbench và JSA Test Suite, minh chứng cho tính ưu việt của framework được đề xuất.
Bảng 1: Sự khác biệt cơ bản giữa Valbench và JSA Test Suite
| Tiêu chí | JSA Test Suite | Valbench |
| Số lượng Test Cases | Nhỏ (khoảng 328 test cases) | Lớn (431 test cases: 372 JVM + 59 Android) |
| Tạo Ground Truth | Thủ công (dễ sai sót) | Tự động hóa (thực thi trên JVM) |
| Độ chính xác Ground Truth | Chứa lỗi (ví dụ: sai hashcode mảng) | Chính xác tuyệt đối (do chạy thực tế) |
| Phạm vi thách thức (Challenges) | Hạn chế (ít mảng, ít vòng lặp) | Đa dạng (Reflection, Streams, Android Intents) |
| Thống kê Mảng (Arrays) | 12.50% số test cases | 28.54% số test cases |
| Thống kê Vòng lặp (Loops) | 4.57% số test cases | 23.20% số test cases |
| Hỗ trợ Android | Không | Có (59 test cases đặc thù) |
| Tính độc lập | Phụ thuộc vào JSA | Độc lập hoàn toàn (Platform independent) |
| Mục tiêu đánh giá | Phân tích chuỗi (String Analysis) | Phân tích giá trị chính xác (Exact Value Analysis) |
4. Kết quả phân tích
4.1. Thiết lập thực nghiệm
Bộ benchmark Valbench được sử dụng để đánh giá 7 công cụ phân tích giá trị hiện có. Valbench bao gồm tổng cộng 431 trường hợp thử nghiệm (372 trường hợp thử nghiệm JVM, 59 trường hợp thử nghiệm Android). Các công cụ được đánh giá bao gồm: công cụ dựa trên biểu thức chính quy: BlueSeal, Coal, JSA, Violist; công cụ giá trị cụ thể: Harvester, StringHound, ValDroid.
Để chuẩn bị cho việc đánh giá, các công cụ JSA, Violist, BlueSeal, và Coal đã được điều chỉnh để sử dụng bản phát hành Soot mới nhất nhằm đảm bảo khả năng phân tích các tệp lớp Java hiện đại7. StringHound cũng được sửa đổi để phân loại các phương thức test case là phương thức giải mã chuỗi để sử dụng thuật toán slicing của nó. Đối với các trường hợp thử nghiệm Android, các phiên bản Android của các trường hợp thử nghiệm đã được sử dụng cho Harvester, Coal, BlueSeal và ValDroid.
4.2. Kết quả tổng thể
Kết quả đánh giá tổng thể (Precision/Recall) trên các trường hợp thử nghiệm JVM và Android được trình bày trong Bảng dưới đây.
Bảng 2: Kết quả đánh giá tổng thể các trường hợp thử nghiệm
| Approach | Prec. (JVM) | Rec. (JVM) | Prec. (Android) | Rec. (Android) |
| BlueSeal | 2.39 | 1.95 | 0 | 0 |
| Coal | 10.34 | 6.57 | 0 | 0 |
| Harvester* | 67.67 | 54.50 | 92.86 | 86.67 |
| JSA | 18.73 | 0.02 | N/A | N/A |
| StringHound | 72.53 | 16.06 | N/A | N/A |
| ValDroid* | 91.81 | 90.02 | 94.83 | 91.67 |
| Violist | 9.00 | 0.39 | N/A | N/A |
Kết quả cho thấy, sự khác biệt rõ rệt về hiệu suất giữa hai nhóm công cụ.
Công cụ giá trị cụ thể (Harvester, StringHound, ValDroid): nhóm này, đặc biệt là ValDroid, có độ chính xác (Precision) và độ thu hồi (Recall) cao hơn đáng kể so với các công cụ dựa trên regex. ValDroid đạt độ chính xác 91.81% và độ thu hồi 90.02% trên các trường hợp JVM. Trên các trường hợp Android-specific, ValDroid và Harvester cũng thể hiện hiệu suất cao, với ValDroid đạt 94.83% Prec. và 91.67% Rec.
Công cụ dựa trên biểu thức chính quy (BlueSeal, Coal, JSA, Violist): nhóm này có độ chính xác thấp hơn và độ thu hồi rất thấp (đa số dưới 10%) trên 372 trường hợp thử nghiệm JVM. Valbench cho phép phân tích hiệu suất của các công cụ đối với các thách thức cụ thể.
(1) Thử thách về Mảng
Trường hợp thử nghiệm testArraySensitivity (Listing 2) yêu cầu công cụ phải nhận ra giá trị cụ thể được gán cho phần tử mảng ở chỉ mục 1 là “Right”. JSA trả về quá ước lượng là “Wrong”, “Right” và null.Coal trả về “Wrong” và “Right”. StringHound không đưa ra kết quả cho trường hợp này. Các công cụ khác (Harvester, ValDroid, BlueSeal, Violist) đưa ra kết quả đúng. Điều này cho thấy, các công cụ dựa trên biểu thức chính quy gặp khó khăn trong việc xử lý chính xác tính nhạy cảm của mảng.
(2) Thử thách về Vòng lặp
Trường hợp simpleLoopTest (Listing 4) là một vòng lặp xây dựng một chuỗi phức tạp.StringHound, Harvester, ValDroid báo cáo chuỗi chính xác: Start-01234-afterLoop.JSA quá ước lượng với biểu thức chính quy rộng Start-(.*). Violist trả về giá trị sai nullafterLoop. Coal trả về bốn biểu thức chính quy quá ước lượng khác nhau. Hiệu suất trên các bài kiểm tra Vòng lặp tổng thể cũng khẳng định điều này: ValDroid và Harvester đạt độ chính xác và độ thu hồi gần 95% và 100% tương ứng, trong khi JSA, Coal và Violist đều có độ thu hồi 0%.
(3) Thử thách về Streams
Các trường hợp thử nghiệm liên quan đến Streams như testInputStream3 và testInputStream4 là đặc biệt khó khăn. JSA quá ước lượng kết quả, dẫn đến 253,948 false positives cho mỗi trường hợp thử nghiệm (cho mỗi kết hợp ký tự ASCII có thể được trả về). Chỉ có Harvester và ValDroid trả về các giá trị chính xác cho các trường hợp này. Kết quả chi tiết cho thấy, ValDroid trả về giá trị đúng cho 27/29 trường hợp stream, trong khi StringHound chỉ 4 và Harvester chỉ 532.
(4) Thảo luận
Sự chênh lệch lớn về hiệu suất (Prec/Rec) giữa các công cụ giá trị cụ thể và các công cụ dựa trên biểu thức chính quy nhấn mạnh một vấn đề cốt lõi: Regex là sự quá ước lượng, trong nhiều trường hợp, việc các công cụ như JSA trả về biểu thức chính quy rộng (ví dụ:.*) thay vì giá trị cụ thể là do sự thiếu chính xác cố hữu của thuật toán. Valbench với mặt đất sự thật luôn là một giá trị cụ thể, phạt nặng các biểu thức chính quy quá rộng. Thiếu thông tin là việc trả về các biểu thức chính quy quá rộng như .* (tương đương với wildcard) hoặc không trả về gì cho thấy phân tích tĩnh không thể tìm thấy thông tin cụ thể mà người dùng cần.
Mặc dù các công cụ dựa trên biểu thức chính quy có hiệu suất thấp trên Valbench vốn tập trung vào giá trị chính xác, chúng vẫn có giá trị trong các tình huống khác. Các công cụ dựa trên regex có thể xử lý các giá trị phụ thuộc vào đầu vào bên ngoài không có sẵn cho phân tích tĩnh (ví dụ: đầu vào của người dùng, kết quả từ máy chủ từ xa) bằng cách trả về biểu thức chính quy. Tuy nhiên, sự cần thiết phải trả về regex thay vì giá trị cụ thể thường là hậu quả của sự không chính xác nội tại của thuật toán phân tích.
5. Kết luận
Bài viết chỉ ra khoảng trống quan trọng trong lĩnh vực phân tích giá trị (value analysis) của phân tích tĩnh chương trình: thiếu một bộ benchmark chuẩn có ground truth rõ ràng để đánh giá và so sánh khách quan các công cụ hiện có. Trước thực trạng đó, ValBench như một framework đánh giá toàn diện, cho phép đo lường chính xác độ chính xác (precision), độ bao phủ (recall) và hiệu năng (performance) của các phương pháp phân tích. Thông qua việc kết hợp thực thi cụ thể để tạo ground truth và cơ chế adapter linh hoạt cho nhiều công cụ khác nhau, ValBench không chỉ cung cấp môi trường đánh giá chuẩn hóa mà còn giúp làm rõ những điểm mạnh, điểm yếu và sự đánh đổi giữa độ chính xác và chi phí tính toán của từng phương pháp. Nghiên cứu cũng hệ thống hóa nền tảng lý thuyết liên quan như abstract interpretation, symbolic execution và constraint solving, từ đó đặt ValBench vào bối cảnh học thuật rộng hơn của phân tích chương trình.
Nhìn chung, ValBench đóng vai trò như một bước tiến quan trọng hướng tới việc chuẩn hóa đánh giá trong phân tích giá trị. Công trình này không chỉ hỗ trợ so sánh khách quan giữa các công cụ hiện tại mà còn tạo nền tảng thúc đẩy các nghiên cứu tiếp theo phát triển phương pháp phân tích chính xác, hiệu quả và có tính thực tiễn cao hơn.
Tài liệu tham khảo:
1. A. S. Christensen, A. Møller, and M. I. Schwartzbach (2003). Precise Analysis of String Expressions in Proc. 10th Int. Conf. on Static Analysis (SAS’03), San Diego, CA, USA, Springer-Verlag, Berlin, Heidelberg, pp. 1–18, 2003. Available: http://dl.acm.org/citation.cfm?id=1760267.1760269
2. D. Octeau, D. Luchaup, M. Dering, S. Jha, and P. McDaniel (2015). Composite Constant Propagation: Application to Android InterComponent Communication Analysis in Proc. IEEE/ACM 37th Int. Conf. on Software Engineering (ICSE), vol. 1, 2015, pp. 77–88. Available: https://doi.org/10.1109/ICSE.2015.30
3. D. Li, Y. Lyu, M. Wan, and W. G. J. Halfond (2015). String Analysis for Java and Android Applications in Proc. 10th Joint Meeting on Foundations of Software Engineering (ESEC/FSE 2015), Bergamo, Italy, ACM, New York, NY, USA, pp. 661–672, 2015. Available: https://doi.org/10.1145/2786805.2786879
4. J. D. Vecchio, F. Shen, K. M. Yee, B. Wang, S. Y. Ko, and L. Ziarek (2015). String Analysis of Android Applications (N) in Proc. 30th IEEE/ACM Int. Conf. on Automated Software Engineering (ASE), 2015, pp. 680– 685. Available: https://doi.org/10.1109/ASE.2015.20
5. S. Rasthofer, S. Arzt, M. Miltenberger and E. Bodden (2016). Harvesting Runtime Values in Android Applications That Feature Anti-Analysis Techniques in Proc. NDSS.
6. L. Glanz, P. M¨uller, L. Baumg¨artner, M. Reif, S. Amann, P. Anthonysamy, and M. Mezini (2020). Hidden in Plain Sight: Obfuscated Strings Threatening Your Privacy in Proc. 15th ACM Asia Conference on Computer and Communications Security (ACM Asia CCS). https://doi.org/10.1145/3320269.3384745
7. M. Miltenberger and S. Arzt (2024). Precisely Extracting Complex Variable Values from Android Apps ACM Trans. Softw. Eng. Methodol. https://doi.org/10.1145/3649591



