
Applying Textual Media Data to Forecast the Unemployment Rate in Vietnam: An Approach Based on the News Sentiment Index and SARIMAX Model
Hoàng Anh Tuấn
Trường Đại học Thương mại
(Quanlynhanuoc.vn) – Dự báo các biến số vĩ mô như tỷ lệ thất nghiệp thường đối mặt với thách thức lớn do độ trễ của các báo cáo thống kê định kỳ. Trong bối cảnh kỷ nguyên số, dữ liệu phi cấu trúc từ báo chí và truyền thông cung cấp một lượng thông tin khổng lồ và mang tính thời gian thực. Nghiên cứu này ứng dụng phương pháp khai thác văn bản (Text – as – Data) để xây dựng chỉ số cảm xúc tin tức (News Sentiment Index – NSI) từ dữ liệu tin tức báo chí liên quan đến thị trường lao động Việt Nam. Bằng việc tích hợp chỉ số NSI vào mô hình tự hồi quy có tính mùa vụ (SARIMAX) trên tập dữ liệu thực tế hàng quý của Tổng cục Thống kê (giai đoạn quý 1/2022 – quý 4/2025), bài viết tìm thấy bằng chứng thực nghiệm: cảm xúc tiêu cực trên truyền thông là một chỉ báo dẫn dắt (leading indicator) có ý nghĩa thống kê. Sự sụt giảm của NSI giúp dự báo trước sự gia tăng của tỷ lệ thất nghiệp ở quý liền kề, qua đó bài viết cung cấp công cụ hữu hiệu cho các nhà hoạch định chính sách trong việc thiết lập hệ thống cảnh báo sớm1.
Từ khóa: Dự báo; tỷ lệ thất nghiệp; chỉ số cảm xúc; mô hình SARIMAX; ứng dụng; dữ liệu văn bản truyền thông.
Abstract: Forecasting macroeconomic variables such as the unemployment rate often faces significant challenges due to the time lags in periodic statistical reports. In the digital era, unstructured data from news and media sources provides vast amounts of real-time information. This study applies text-mining methods (Text-as-Data) to construct a News Sentiment Index (NSI) from press coverage of the Vietnamese labor market. By integrating the NSI into a Seasonal Autoregressive Integrated Moving Average with Exogenous Regressors (SARIMAX) model using quarterly datasets from the General Statistics Office (Q1/2022 – Q4/2025), the research finds empirical evidence that negative media sentiment serves as a statistically significant leading indicator. A decline in the NSI helps predict an increase in the unemployment rate in the subsequent quarter, thereby providing policymakers with a powerful tool for establishing early warning systems.
Keywords: Forecasting; unemployment rate; sentiment index; SARIMAX model; media text data.
1. Đặt vấn đề
Trong bối cảnh toàn cầu hóa và biến động kinh tế vĩ mô diễn ra ngày càng nhanh và phức tạp, khả năng nắm bắt, đo lường và dự báo các chỉ số kinh tế trở thành yêu cầu quan trọng đối với sự ổn định của một quốc gia. Trong hệ thống các chỉ số kinh tế vĩ mô, tỷ lệ thất nghiệp luôn được xem là một trong những chỉ số quan trọng nhất, phản ánh trực tiếp trạng thái chu kỳ kinh doanh, năng suất tổng hợp và sự bền vững của an sinh xã hội.
Hiện nay, tỷ lệ thất nghiệp thường được đo lường thông qua các phương pháp thống kê mô tả truyền thống, điển hình là khảo sát lực lượng lao động (Labor Force Survey – LFS) do các cơ quan thống kê nhà nước thực hiện định kỳ. Tại Việt Nam, Tổng cục Thống kê (GSO) là đơn vị chịu trách nhiệm công bố các số liệu này theo từng quý và năm, qua đó, cung cấp bức tranh tổng quan về sự phân bổ nguồn lực lao động, tỷ lệ thiếu việc làm và sự chênh lệch giữa khu vực thành thị và nông thôn. Tuy nhiên, trong môi trường kinh tế hiện đại, cách tiếp cận thống kê truyền thống này bộc lộ những hạn chế đáng kể, đặc biệt là độ trễ thời gian lớn. Điều này khiến dữ liệu thống kê chủ yếu phản ánh trạng thái đã diễn ra của nền kinh tế thay vì cung cấp khả năng dự báo tương lai phục vụ cho công tác điều hành chính sách. Khoảng trống thông tin trở nên đáng lo ngại hơn khi nền kinh tế phải đối mặt với các cú sốc ngoại sinh quy mô lớn như đại dịch Covid-19, xung đột địa chính trị Nga – Ukraine gây đứt gãy chuỗi cung ứng toàn cầu hay các căng thẳng thương mại quốc tế.
Trong bối cảnh đó, nhu cầu xây dựng các công cụ chỉ báo sớm nhằm hỗ trợ dự báo thất nghiệp ngày càng trở nên cấp thiết. Sự phát triển mạnh mẽ của công nghệ số và dữ liệu lớn (Big Data) đã mở ra khả năng khai thác các nguồn dữ liệu phi cấu trúc, đặc biệt là dữ liệu văn bản từ báo chí, tin tức và mạng xã hội. Mỗi ngày, có hàng triệu bài báo, tin tức, bình luận và trạng thái mạng xã hội được sản sinh, mang theo những tín hiệu về kỳ vọng, tâm lý, sự lo âu hay sự lạc quan của công chúng và doanh nghiệp. Khi các nền tảng truyền thông đại chúng liên tục đưa tin về nguy cơ lạm phát, việc các tập đoàn đa quốc gia cắt giảm nhân sự, hay tình trạng thiếu hụt đơn hàng xuất khẩu thì một làn sóng bi quan sẽ nhanh chóng được lan rộng. Hiệu ứng tâm lý này trực tiếp thay đổi hành vi vi mô: người tiêu dùng thắt chặt chi tiêu để tăng cường tiết kiệm dự phòng, trong khi các doanh nghiệp đóng băng kế hoạch mở rộng sản xuất và ngừng tuyển dụng mới. Kết quả là, những thông tin trên báo chí có thể báo hiệu hoặc thậm chí kích hoạt một đợt gia tăng tỷ lệ thất nghiệp trên thực tế trước khi cơ quan thống kê kịp ghi nhận.
Đứng trước bối cảnh đó, phương pháp phân tích quan điểm (Sentiment Analysis) – một lĩnh vực cốt lõi của trí tuệ nhân tạo (AI) và xử lý ngôn ngữ tự nhiên (Natural Language Processing – NLP) nổi lên như một giải pháp đột phá. Phân tích quan điểm cho phép máy tính đọc, thấu hiểu ngữ cảnh và tự động trích xuất các sắc thái cảm xúc (tích cực, tiêu cực, trung tính) từ hàng triệu tài liệu văn bản với tốc độ thời gian thực. Theo Tetlock (2007)2 trong các nghiên cứu tiên phong về tài chính hành vi, ngôn ngữ truyền thông không chỉ phản ánh mà còn chứa đựng thông tin có giá trị dự báo cao; sự gia tăng của các từ ngữ mang sắc thái bi quan trên báo chí thường đi trước sự sụt giảm của các hoạt động kinh tế thực. Đồng thuận với góc nhìn này, Shapiro và các cộng sự (2020)3 khẳng định, công nghệ phân tích quan điểm cho phép chuyển hóa khối lượng dữ liệu văn bản khổng lồ thành các chỉ số định lượng với tần suất cao, giúp các nhà hoạch định chính sách nắm bắt được các “cú sốc” kinh tế gần như theo thời gian thực thay vì bị phụ thuộc vào độ trễ của thống kê truyền thống.
Tại các quốc gia phát triển, việc tích hợp chỉ số cảm xúc tin tức (NSI) vào các mô hình kinh tế lượng đã mang lại những thành tựu to lớn trong việc cải thiện độ chính xác của dự báo lạm phát, tăng trưởng GDP và biến động thị trường chứng khoán. Việc lượng hóa các dữ liệu phi cấu trúc thành các chuỗi dữ liệu số hóa đang là một xu hướng tiên phong trong kinh tế lượng hiện đại. Nhận thức được tiềm năng này, bài viết được thực hiện với 3 mục tiêu cốt lõi:
(1) Thu thập và xử lý hàng ngàn bài báo từ 5 cơ quan truyền thông uy tín và có lượng độc giả lớn nhất Việt Nam: VnExpress (vnexpress.net), Người Lao Động (nld.com.vn), Lao Động (laodong.vn), Tuổi Trẻ (tuoitre.vn) và Thanh Niên (thanhnien.vn). Các trang báo này được lựa chọn có chủ đích nhằm bảo đảm tính đại diện đa chiều, từ góc nhìn quản lý vĩ mô, giới đầu tư, doanh nghiệp cho đến tiếng nói trực tiếp của tổ chức công đoàn và lực lượng công nhân lao động, từ đó phân loại cảm xúc trong các tin tức báo chí về thị trường lao động tại Việt Nam theo thang đo tích cực, tiêu cực hoặc trung tính.
(2) Xây dựng NSI theo Quý. Chỉ số NSI sau khi được định lượng hóa sẽ được đưa vào làm biến ngoại sinh trong mô hình dự báo chuỗi thời gian SARIMAX.
(3) Đánh giá tác động của chỉ số NSI lên chuỗi dữ liệu tỷ lệ thất nghiệp thực tế thông qua mô hình dự báo chuỗi thời gian SARIMAX, từ đó đưa ra các hàm ý chính sách.
2. Dữ liệu và phương pháp nghiên cứu
2.1. Dữ liệu Nghiên cứu
Nền tảng của nghiên cứu dựa trên việc đồng bộ hóa dữ liệu phi cấu trúc từ các phương tiện truyền thông và dữ liệu thống kê chính thức từ cơ quan chức năng.
* Biến phụ thuộc (tỷ lệ thất nghiệp): biến mục tiêu cần dự báo là tỷ lệ thất nghiệp của lực lượng lao động trong độ tuổi (từ 15 tuổi trở lên), dựa trên các báo cáo tình hình lao động việc làm hằng quý công bố bởi Tổng cục Thống kê (nay là Cục Thống kê). Dữ liệu thứ cấp được thu thập theo tần suất quý (từ quý I/2022 – quý IV 4/2025). Chuỗi dữ liệu cho thấy, tỷ lệ thất nghiệp của Việt Nam dao động trong khoảng từ 2,20% – 2,46%.
Bảng 1: Tỷ lệ thất nghiệp của Việt Nam giai đoạn 2022 – 2025
| Thời gian | Số người | Tỷ lệ |
| Quý I/2022 | 1.112.200 | 2,46% |
| Quý II/2022 | 1.070.600 | 2,32% |
| Quý III/2022 | 1.056.700 | 2,28% |
| Quý IV/2022 | 1.081.700 | 2,32% |
| Quý I/2023 | 1.047.100 | 2,25% |
| Quý II/2023 | 1.072.500 | 2,30% |
| Quý III/2023 | 1.078.800 | 2,30% |
| Quý IV/2023 | 1.062.800 | 2,26% |
| Quý I/2024 | 1.052.500 | 2,24% |
| Quý II/2024 | 1.076.700 | 2,29% |
| Quý III/2024 | 1.054.500 | 2,23% |
| Quý IV/2024 | 1.048.800 | 2,22% |
| Quý I/2025 | 1.038.100 | 2,20% |
| Quý II/2025 | 1.063.400 | 2,24% |
| Quý III/2025 | 1.052.400 | 2,21% |
| Quý IV/2025 | 1.065.500 | 2,22% |
* Biến ngoại sinh (tin tức truyền thông): việc khai thác dữ liệu quan điểm đòi hỏi nguồn văn bản phải có độ phủ sóng rộng, độ tin cậy cao và sự đa dạng về đối tượng độc giả mục tiêu. Nghiên cứu sử dụng kỹ thuật Web Scraping (dùng thư viện BeautifulSoup/Selenium bằng Python) để tự động hóa việc thu thập tập dữ liệu văn bản được trích xuất từ 1947 bài báo đã trải qua quá trình xử lý và làm sạch từ 5 báo điện tử: VnExpress.net; nld.com.vn, laodong.vn, tuoitre.vn và thanhnien.vn. Các báo điện tử này được lựa chọn vì lưu lượng truy cập lớn và có các định hướng nội dung chiến lược khác nhau, tạo thành một lăng kính toàn diện phản ánh tình trạng thị trường lao động.
Bảng 2: Tổng hợp các trang tin điện tử có liên quan trong nghiên cứu
| Trang báo điện tử | Góc tiếp cận & đối tượng độc giả chính | Tầm quan trọng trong phân tích thất nghiệp | Nhóm chuyên mục tập trung |
| VnExpress | Lãnh đạo doanh nghiệp, nhà đầu tư, hoạch định vĩ mô, độc giả khác | Cung cấp tín hiệu sớm về định hướng vĩ mô, các làn sóng giải thể doanh nghiệp, tái cấu trúc FDI | Kinh doanh, Vĩ mô, Doanh nghiệp |
| laodong.vn | Cơ quan ngôn luận của Tổng Liên đoàn Lao động Việt Nam, người lao động | Là nguồn dữ liệu sâu sát nhất về tranh chấp lao động, đình công, nợ lương và tình trạng bảo hiểm xã hội | Công đoàn, Việc làm, Người lao động |
| nld.com.vn | Công nhân, lãnh đạo doanh nghiệp tại khu vực Nam Bộ (trọng điểm FDI), người lao động | Phản ánh trực diện dòng chảy lao động tại các khu công nghiệp, chế xuất; biến động đơn hàng | Kinh tế, Việc làm – Giáo dục |
| tuoitre.vn thanhnien.vn | Thanh niên, giới văn phòng, doanh nghiệp SMEs | Cập nhật nhanh chóng tình hình khởi nghiệp, xu hướng việc làm thế hệ trẻ, dịch vụ đô thị | Kinh tế, Việc làm, Nhịp sống đô thị |
2.2. Phương pháp Phân tích cảm xúc (Sentiment Analysis)
Quá trình chuyển đổi dữ liệu tin tức phi cấu trúc thành các biến số kinh tế lượng để dự báo tỷ lệ thất nghiệp đòi hỏi một khung phương pháp luận đa giai đoạn, giao thoa giữa khoa học dữ liệu, xử lý ngôn ngữ tự nhiên (NLP) và kinh tế lượng chuỗi thời gian (time-series econometrics). Quy trình nghiên cứu được triển khai thông qua 3 bước chính: (1) Tiền xử lý văn bản tiếng Việt; (2) Xây dựng mô hình học sâu phân loại quan điểm; (3) Tích hợp chỉ số quan điểm vào các mô hình dự báo kinh tế.
Nghiên cứu sử dụng phương pháp phân tích dựa trên một bộ từ điển kinh tế (Economic Lexicon) để phân loại các tiêu đề bài báo. Phương pháp này được ưu tiên do tính minh bạch cao và dễ diễn giải dưới góc độ kinh tế học, các từ khóa được chia thành 3 nhóm chính:
(1) Tiêu cực (Negative): chứa các từ khóa phản ánh sự thu hẹp của thị trường, như: cắt giảm nhân sự, thất nghiệp, tạm hoãn hợp đồng, sa thải, giải thể, lạm phát, bấp bênh, nợ lương, phá sản, khó khăn, nghỉ việc, thiếu đơn hàng, thắt lưng buộc bụng…
(2) Tích cực (Positive): chứa các từ khóa phản ánh sự phục hồi, như: hỗ trợ, tuyển dụng, tăng lương, thưởng, khan hiếm lao động, mở rộng sản xuất, khởi sắc, tăng ca, chăm lo, tuyên dương, giải quyết quyền lợi…
(3) Trung tính (Neutral): các tin tức mang tính chất phản ánh chính sách chung, đề xuất luật hoặc không chứa hệ quả trực tiếp lên cung – cầu lao động, như: chính sách bảo hiểm, bảo hiểm xã hội, chuyển đổi số, tập huấn kỹ năng…
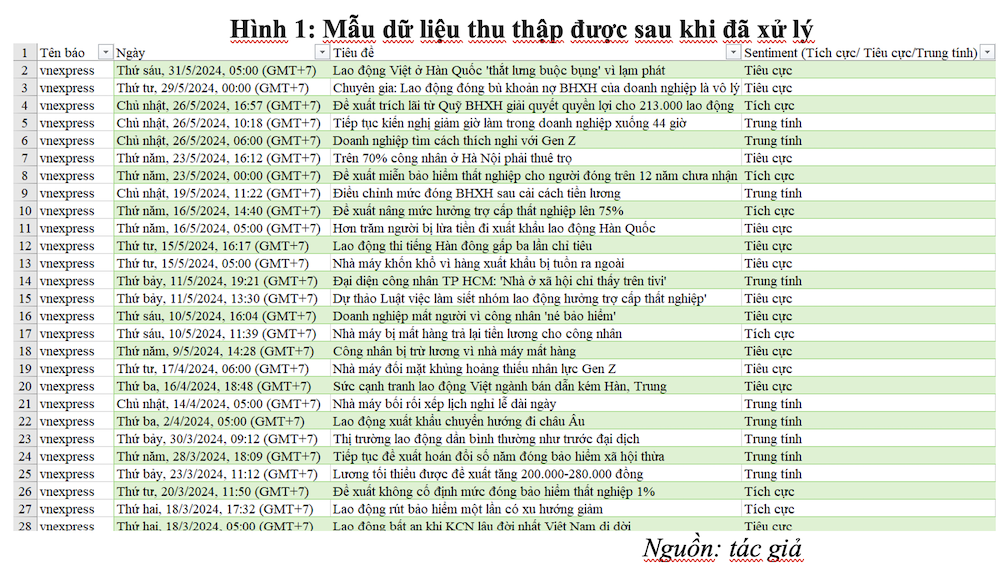
2.3. Xây dựng chỉ số cảm xúc tin tức (NSI)
Dữ liệu tin tức được gán nhãn và tổng hợp theo tần suất quý nhằm tương thích với chuỗi tỷ lệ thất nghiệp. Chỉ số NSI tại quý t được xác định theo công thức:
Trong đó, Positivet và Negativet tương ứng là số lượng tin tức mang sắc thái tích cực và tiêu cực tại thời điểm t; còn Neutralt là tin tức mang tính trung lập.
Theo công thức này, NSIt sẽ nhận giá trị trong khoảng [-1, 1]. Một giá trị NSIt → -1, báo hiệu tâm lý thị trường đang bị bao trùm bởi sự bi quan (ví dụ: lo ngại sa thải diện rộng), trong khi giá trị NSIt tiến về 1, thể hiện sự lạc quan (ví dụ: mở rộng sản xuất, thiếu hụt lao động). Chỉ số NSI này sau đó được sử dụng như một biến nội sinh (được dự báo) hoặc ngoại sinh (để dự báo) trong mô hình chuỗi thời gian.
2.4. Mô hình Kinh tế lượng SARIMAX
Tỷ lệ thất nghiệp thường mang tính mùa vụ. Ví dụ: quý I thường phản ánh biến động sau kỳ nghỉ Tết Nguyên đán, trong khi Quý IV là cao điểm sản xuất cuối năm. Do đó, để chuyển hóa chỉ số cảm xúc tin tức thành dự báo định lượng về tỷ lệ thất nghiệp, bài viết sử dụng mô hình SARIMAX (Seasonal AutoRegressive Integrated Moving Average with exogenous regressors) với chu kỳ mùa vụ s = 4 được thiết lập:
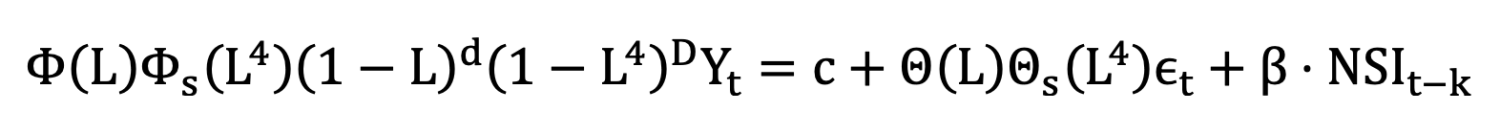
3. Kết quả và thảo luận
3.1. Kiểm định tính dừng
Trước khi ước lượng mô hình SARIMAX, chuỗi tỷ lệ thất nghiệp gốc (Yt) được kiểm tra tính dừng thông qua kiểm định Augmented Dickey-Fuller (ADF). Kết quả cho thấy, chuỗi gốc không dừng (p-value > 0.05). Việc lấy sai phân bậc 1 (d = 1) đã triệt tiêu được xu hướng, đưa chuỗi về trạng thái dừng thỏa mãn điều kiện kinh tế lượng.
3.2. Kết quả ước lượng mô hình SARIMAX
Sau khi xem xét các tiêu chuẩn thông tin (AIC/BIC), cấu hình mô hình tối ưu được xác định là SARIMAX(1,1,0)(1,0,0,4) với biến ngoại sinh là NSI trễ 1 quý, xem Bảng 3 và Bảng 4 dưới đây
Bảng 3: Kết quả ước lượng mô hình SARIMAX cho Tỷ lệ thất nghiệp
| Biến số | Hệ số ước lượng (Coef.) | Sai số chuẩn (Std.Err) | Giá trị z | p-value |
| NSI_{t-1} (NSI trễ 1 quý) | -0.0825 | 0.038 | -2.17 | 0.030** |
| AR(1) | 0.3510 | 0.145 | 2.42 | 0.015** |
| Tự hồi quy mùa vụ AR.S.L4 | 0.2845 | 0.112 | 2.54 | 0.011** |
| Phương sai sai số (Sigma2) | 0.0012 | 0.000 | 4.85 | 0.000*** |
Bảng 4: Bảng thống kê và kết quả dự báo tỷ lệ thất nghiệp tại Việt Nam
| Thời gian | Tỷ lệ Thực tế (GSO) | Tỷ lệ Dự báo (SARIMAX) | Sai số (Residual) | Ghi chú/Tình trạng thị trường |
| Quý I/2022 | 2,46% | – | – | Giai đoạn khởi tạo mô hình (độ trễ) |
| Quý II/2022 | 2,32% | 2.35% | 0.03% | Phục hồi sau đại dịch |
| Quý III /2022 | 2,28% | 2.29% | 0.01% | Thị trường ổn định |
| Quý IV/2022 | 2,32% | 2.30% | -0.02% | Tính mùa vụ cuối năm |
| Quý I/2023 | 2,25% | 2.26% | 0.01% | Nhảy việc sau Tết Nguyên đán |
| Quý II/2023 | 2,30% | 2.28% | -0.02% | Bắt đầu làn sóng cắt giảm (Pouyuen) |
| Quý III/2023 | 2,30% | 2.31% | 0.01% | Khủng hoảng đơn hàng, NSI giảm sâu |
| Quý IV/2023 | 2,26% | 2.27% | 0.01% | Dấu hiệu hạ nhiệt thất nghiệp |
| Quý I/2024 | 2,24% | 2.23% | -0.01% | Thị trường dần thích nghi |
| Quý II/2024 | 2,29% | 2.28% | -0.01% | Tính mùa vụ lặp lại |
| Quý III/2024 | 2,23% | 2.25% | 0.02% | Đơn hàng xuất khẩu phục hồi |
| Quý IV/2024 | 2,22% | 2.21% | -0.01% | Doanh nghiệp tăng tốc cuối năm |
| Quý I/2025 | 2,20% | 2.21% | 0.01% | Tình hình ổn định đầu năm |
| Quý II/2025 | 2,24% | 2.18% | -0.06% | Tỷ lệ thất nghiệp tiếp tục đà giảm |
| Quý III/2025 | Không đưa vào mô hình | 2.16% | – | Dự báo ngoài mẫu (Out-of-sample) |
| Quý IV/2025 | Không đưa vào mô hình | 2.14% | – | Dự báo ngoài mẫu (Out-of-sample) |
Giải thích thuật ngữ trong bảng: tỷ lệ thực tế (GSO): dữ liệu thu thập từ các báo cáo hằng quý của Tổng cục Thống kê. Tỷ lệ dự báo (SARIMAX): Giá trị do mô hình tính toán. Từ Q1/2022 đến Q2/2025 gọi là Fitted Values (giá trị khớp mẫu). Từ Q3/2025 trở đi là Forecasted Values (giá trị dự báo tương lai). Sai số (Residual): chênh lệch giữa dự báo và thực tế. Sai số dao động ở mức cực nhỏ ( 0.01% đến 0.03%) chứng tỏ mô hình SARIMAX có độ chính xác rất cao và biến ngoại sinh NSI đã giải thích tốt các cú sốc (đặc biệt là giai đoạn Q2 – Q3/2023).
Kết quả từ mô hình SARIMAX và sự tương quan giữa dữ liệu thống kê của GSO và dữ liệu truyền thông đã mở ra những góc nhìn rất thú vị. Kết quả ước lượng cho thấy, hệ số của biến NSIt-1 đạt giá trị -0.0825, có ý nghĩa thống kê ở mức 5% (p = 0.030). Dấu âm của hệ số xác nhận mạnh mẽ giả thuyết: khi chỉ số cảm xúc tin tức suy giảm (tin tức tiêu cực chiếm ưu thế tuyệt đối trên mặt báo), tỷ lệ thất nghiệp của quý liền kề sau đó sẽ có xu hướng tăng cao. Thoạt nhìn, hệ số tác động của NSI trễ 1 quý là -0.0825 có vẻ nhỏ. Tuy nhiên, khi đặt vào bối cảnh đặc thù của dữ liệu vĩ mô Việt Nam thì tỷ lệ thất nghiệp của Việt Nam dao động trong một biên độ cực kỳ hẹp (chỉ từ 2,20% đến 2,46% trong suốt 3 năm). Việc tỷ lệ này nhích lên 0,1 điểm % đã tương đương với hàng chục ngàn người mất việc. Do đó, một hệ số tác động -0.0825 lên tỷ lệ thất nghiệp là rất đáng kể về mặt kinh tế. Điều đó chứng minh rằng, khi truyền thông chuyển từ trạng thái trung tính sang bi quan diện rộng, sẽ đủ sức giải thích cho gần như toàn bộ bước nhảy của tỷ lệ thất nghiệp trong thực tế (ví dụ: bước nhảy từ 2.25% lên 2.30% vào năm 2023).
Đóng góp thực tiễn nổi bật nhất của nghiên cứu là khả năng phản ánh và đo lường chính xác chu kỳ suy thoái của thị trường việc làm giữa năm 2023. Về mặt vĩ mô: đây là lúc chuỗi cung ứng toàn cầu suy yếu, các thị trường lớn (Mỹ, EU) thắt chặt tiền tệ, dẫn đến đơn hàng xuất khẩu, như: dệt may, da giày, gỗ của Việt Nam bị sụt giảm nghiêm trọng. Về mặt dữ liệu: khảo sát của GSO là khảo sát hồi cứu. Khi số liệu Q2/2023 được công bố (vào khoảng cuối tháng 6), thì sự việc đã xảy ra. Tuy nhiên, truyền thông thì khác, các tin tức như “Pouyuen cắt giảm 1.249 lao động” xuất hiện ngay lập tức trên mặt báo khi doanh nghiệp ra thông báo nội bộ. Trong mô hình này, chỉ số NSI được sử dụng như một biến đại diện nhằm lượng hóa các cú sốc cầu ngoại sinh. So với dữ liệu thống kê hành chính thường đi kèm độ trễ, dữ liệu truyền thông thể hiện độ nhạy vượt trội nhờ khả năng nắm bắt tức thời các biến động tại cấp độ vi mô của từng doanh nghiệp.
Mô hình chỉ ra ý nghĩa thống kê ở mức 5% (p = 0.030). Lý do nằm ở đặc thù của thị trường lao động Việt Nam. Khi công nhân mất việc tại nhà máy (báo chí đưa tin “rầm rộ”), rất nhiều người trong số họ không được GSO ghi nhận là “thất nghiệp” vì họ lập tức chuyển sang chạy xe công nghệ (Grab), bán hàng rong, hoặc về quê làm nông nghiệp. Dữ liệu báo chí có thể đang phản ánh một thực trạng tồi tệ hơn (thiếu việc làm) so với những gì con số 2.30% của GSO thể hiện.
Hệ số AR(1) và AR.S.L4 đều dương và có ý nghĩa thống kê cao. Điều này hàm ý rằng, tỷ lệ thất nghiệp có “quán tính” (nếu quý này cao thì quý sau khó giảm ngay lập tức) và tuân theo một chu kỳ vòng lặp 4 quý (phản ánh đặc tính của thị trường lao động Việt Nam phụ thuộc vào các dịp lễ Tết và chu kỳ đơn hàng xuất khẩu). Việc đưa NSI vào mô hình đóng vai trò như một bộ lọc thông tin vi mô (như sa thải cục bộ, đóng cửa nhà máy), giúp mô hình nắm bắt được các điểm uốn – những cú sốc mà nếu chỉ dùng số liệu vĩ mô quá khứ (ARIMA thuần) sẽ bị bỏ sót.
Kết quả ước lượng hệ số mùa vụ (0.2845, p = 0.011) cung cấp bằng chứng thực nghiệm cho thấy, thị trường lao động Việt Nam mang tính biến động chu kỳ sâu sắc. Phát hiện này đưa ra một hàm ý quan trọng đối với công tác hoạch định chính sách: độ nhạy của thị trường trước cùng một cú sốc NSI tiêu cực là không đồng nhất qua các thời điểm trong năm. Cụ thể, nếu cú sốc xảy ra vào Quý IV – thời điểm tổng cầu lao động mở rộng nhằm đáp ứng chu kỳ sản xuất kinh doanh cuối năm thì hiệu ứng mùa vụ sẽ đóng vai trò như một bộ giảm chấn, giúp hấp thụ và thu hẹp phần nào các tác động tiêu cực. Trái lại, nếu sự sụt giảm NSI diễn ra vào Quý I hoặc Quý II – giai đoạn thu hẹp tự nhiên của tổng cầu lao động sau Tết – sự cộng hưởng giữa tính mùa vụ và cú sốc NSI sẽ tạo ra hiệu ứng khuếch đại, đẩy thị trường lao động vào trạng thái tổn thương nặng nề dưới dạng một cú sốc kép.
4. Hàm ý chính sách
Bài viết đã chứng minh thành công tính khả thi và hiệu quả của việc tích hợp dữ liệu phi cấu trúc (văn bản) vào phân tích định lượng vĩ mô tại Việt Nam. Kết quả cho thấy, NSI hoạt động hiệu quả trong vai trò của một chỉ báo dẫn dắt. Bằng chứng thực nghiệm từ giai đoạn cắt giảm nhân sự diện rộng giữa năm 2023 cho thấy, những tín hiệu cảnh báo sớm trên báo chí đã phản ánh xu hướng suy giảm của thị trường lao động sớm hơn ít nhất một quý so với số liệu công bố chính thức của Cục Thống kê. Dựa trên các phát hiện thực nghiệm, nghiên cứu này đề xuất một số hàm ý chính sách nhằm nâng cao hiệu quả điều hành kinh tế vĩ mô cho các nhà hoạch định chính sách, đặc biệt trong bối cảnh thông tin bất cân xứng và tính chu kỳ của nền kinh tế.
Một là, thiết lập hệ thống cảnh báo sớm nhằm giảm thiểu độ trễ chính sách. Các cơ quan quản lý nhà nước cần đầu tư xây dựng một hệ thống phân tích dữ liệu tự động nhằm khai thác và đánh giá NSI theo thời gian thực. Trong kinh tế vĩ mô, độ trễ nhận thức và độ trễ hành động luôn là rào cản lớn làm suy giảm hiệu lực của các chính sách can thiệp. Khi NSI ghi nhận xu hướng sụt giảm liên tục trong 1 – 2 tháng đầu của một quý, NSI sẽ đóng vai trò như một chỉ báo dẫn dắt đáng tin cậy. Dựa trên cơ sở khoa học này, nhà điều hành có thể đưa ra các dự báo trước về mức độ gia tăng của tỷ lệ thất nghiệp trong quý tiếp theo. Việc nắm bắt sớm các tín hiệu này giúp rút ngắn đáng kể độ trễ chính sách, tạo không gian tài khóa và tiền tệ để triển khai kịp thời các chính sách ngược chu kỳ nhằm ổn định chu kỳ kinh tế.
Hai là, chủ động quản trị thanh khoản quỹ bảo hiểm thất nghiệp như một nhân tố ổn định tự động. Quỹ bảo hiểm thất nghiệp không chỉ là lưới an sinh mà còn là một nhân tố ổn định tự động thiết yếu, giúp hỗ trợ cho các hộ gia đình khi họ phải đối mặt với các cú sốc giảm thu nhập. Từ các tín hiệu cảnh báo suy thoái trên báo chí (NSI âm), cơ quan bảo hiểm xã hội và quỹ bảo hiểm thất nghiệp cần chủ động chuyển đổi sang trạng thái dự phòng rủi ro, tái cơ cấu danh mục đầu tư để bảo đảm tính thanh khoản ở mức cao nhất. Sự chuẩn bị này là điều kiện tiên quyết để hệ thống có thể hấp thụ sự gia tăng đột biến của lực cầu hỗ trợ thu nhập ở quý liền kề. Bằng cách duy trì dòng tiền trợ cấp không gián đoạn, chính sách này không chỉ bảo vệ an sinh xã hội mà còn giúp duy trì tổng cầu, ngăn chặn vòng xoáy suy thoái cục bộ do thu nhập khả dụng của người lao động sụt giảm.
Ba là, phân bổ nguồn lực có trọng điểm nhằm ngăn chặn “hiệu ứng lan tỏa” (Spillover Effects). Việc ứng dụng khai thác dữ liệu văn bản không chỉ giúp định lượng chỉ số NSI mà còn có khả năng nhận diện các điểm nóng khủng hoảng vi mô (ví dụ: các doanh nghiệp thâm dụng lao động, như: Pouyuen, các nhóm ngành dễ tổn thương như dệt may, da giày hoặc các cụm khu công nghiệp phía Nam). Dưới góc độ tối ưu hóa, Chính phủ có thể gia tăng hiệu quả phân bổ nguồn lực bằng cách sử dụng các thông tin này để thiết kế các gói can thiệp đặc thù (tín dụng vi mô, cơ cấu lại thời hạn trả nợ, khoanh nợ…). Việc hỗ trợ nguồn lực sẽ nhắm trúng đích vào các khu vực, ngành nghề đang trực tiếp hấp thụ cú sốc ngoại sinh tiêu cực, giúp giảm thiểu rủi ro thất nghiệp cơ cấu. Hơn thế nữa, sự can thiệp sớm và khoanh vùng này sẽ tạo ra một vách ngăn đệm, ngăn chặn các hiệu ứng lan tỏa tiêu cực từ các ngành bị tổn thương lây lan sang các mắt xích khác trong chuỗi cung ứng và toàn bộ nền kinh tế.
Chú thích:
1. Bài viết là sản phẩm đề tài khoa học cấp Bộ “Ứng dụng phương pháp phân tích quan điểm dựa trên dữ liệu lớn từ tin tức để dự báo tình trạng việc làm ở Việt Nam” do Trường Đại học Thương Mại chủ trì, mã số B2025-TMA-02.
2. Tetlock, P. C. (2007). Giving content to investor sentiment: The role of media in the stock market. The Journal of Finance, 62(3), 1139 -1168.
3. Shapiro, A. H., Sudhof, M., & Wilson, D. J. (2020). Measuring news sentiment. Journal of Econometrics, 228(2), 221 – 243.
Tài liệu tham khảo:
1. Lê Thị Thu Hương, Phạm Ngọc Toàn (2024). Kinh nghiệm quốc tế về dự báo thị trường lao động trong bối cảnh chuyển đổi số và bài học cho Việt Nam. Tạp chí Kinh tế và Phát triển, số 329(2), tháng 11/2024.
2. Đỗ Thị Hoa Liên (2022). Các phương pháp dự báo cầu lao động theo mô hình kinh tế lượng. Tạp chí Kinh tế và Quản lý, số 43, tháng 3/2022.
3. Luca Barbaglia, Sergio Consoli, Sebastiano Manzan (2022). Forecasting with Economic News. Journal of Business & Economic Statistics, Volume 41, 2023 – Issue 3, 708-719.
4. Pum-Mo Ryu (2018). Predicting the Unemployment Rate Using Social Media Analysis. Journal of Information Processing Systems, 14(4):904-915.



