
Lê Đình Thái
Trường Đại học Công nghệ TP. Hồ Chí Minh
(Quanlynhanuoc.vn) – Máy học hiện là một công cụ chủ chốt trong nhiều lĩnh vực, bao gồm sản xuất, tiếp thị và thương mại. Máy học mang lại khả năng dự đoán hành vi người tiêu dùng chính xác hơn so với các phương pháp truyền thống, đặc biệt khi áp dụng trên tập dữ liệu lớn đã được huấn luyện kỹ lưỡng. Nhờ đó, các quyết định kinh doanh có thể được tối ưu hóa dựa trên những đặc điểm hành vi của người tiêu dùng. Bài viết trình bày ứng dụng của máy học trong nghiên cứu hành vi người tiêu dùng, với mục tiêu tăng cường khả năng phân tích và dự đoán các quyết định mua sắm. Phương pháp nghiên cứu được áp dụng là nghiên cứu thực nghiệm (Experimental Research) nhằm kiểm tra mối quan hệ nhân quả giữa các biến. Nghiên cứu sử dụng các công cụ như Anaconda, Jupyter Notebook và VSCode để phân tích dữ liệu mô phỏng về tuổi và giới tính, từ đó xây dựng mô hình phân loại bằng thuật toán cây quyết định.
Từ khóa: Hành vi tiêu dùng, máy học, cây quyết định, nghiên cứu hành vi, chỉ số gini.
1. Đặt vấn đề
Những năm gần đây, máy học đã trở thành một trong những công nghệ then chốt, hỗ trợ việc nghiên cứu hiệu quả hơn trên nhiều lĩnh vực của đời sống. Công nghệ này giúp rút ngắn đáng kể thời gian nghiên cứu, từ vài năm xuống còn vài tháng hoặc thậm chí vài tuần trong một số trường hợp. Máy học đã góp phần vào những công trình nghiên cứu đoạt giải Nobel năm 2024 trong các lĩnh vực vật lý và y sinh.
Mặc dù các lĩnh vực nghiên cứu rất đa dạng, hầu hết đều có điểm chung là liên quan đến hành vi con người. Do đó, việc ứng dụng máy học để mô hình hóa và hiểu hành vi này trở thành một hướng đi khả thi và tiềm năng trong nhiều bối cảnh. Bài viết sử dụng các kỹ thuật máy học kết hợp với dữ liệu đầu vào để xây dựng mô hình phân tích hành vi con người. Kết quả của mô hình có thể được ứng dụng trong các hoạt động như sản xuất, tiếp thị và bán hàng nhằm nâng cao hiệu quả ra quyết định.
2. Tổng quan nghiên cứu
Việc ứng dụng các mô hình học máy trong nghiên cứu hành vi người tiêu dùng đang ngày càng phổ biến trong nhiều lĩnh vực, từ thương mại điện tử đến truyền thông và ngân hàng. Các nghiên cứu cho thấy, những mô hình như cây quyết định (decision tree), rừng ngẫu nhiên (random forest), mạng nơ-ron (neural network) hay logistic regression có thể phân tích và dự đoán hành vi khách hàng với độ chính xác cao.
Liu (2012) đã trình bày cách tiếp cận phân tích cảm xúc trong hành vi tiêu dùng thông qua các kỹ thuật học máy, đặc biệt nhấn mạnh vai trò của mô hình học có giám sát trong khai phá dữ liệu từ phản hồi khách hàng. Trong khi đó, Jain và Singh (2018) áp dụng thuật toán cây quyết định để phân loại nhóm khách hàng theo giới tính và độ tuổi, cho thấy khả năng tách lớp tốt với dữ liệu hành vi tiêu dùng cơ bản. Chen và cộng sự (2020) thực hiện khảo sát hệ thống về các thuật toán cây quyết định và chỉ ra rằng mô hình này đặc biệt phù hợp với dữ liệu có cấu trúc đơn giản và mang lại kết quả khả quan trong phân loại khách hàng. Tương tự, Sahu và Singh (2022) cho thấy, việc sử dụng đặc trưng nhân khẩu học (tuổi, giới tính) kết hợp với mô hình học máy có thể cải thiện độ chính xác trong dự đoán sở thích tiêu dùng.
Ngoài ra, các hệ thống đề xuất hiện đại như Amazon và Netflix ứng dụng học sâu (deep learning) và thuật toán dựa trên nhân tố tiềm ẩn để dự đoán và gợi ý sản phẩm theo sở thích người dùng. Huang và Li (2021) nhấn mạnh rằng việc kết hợp nhiều mô hình học máy (ensemble learning) mang lại hiệu suất cao hơn trong cá nhân hóa hành vi khách hàng.
Tóm lại, các nghiên cứu trước đây đều cho thấy, học máy là một công cụ mạnh mẽ trong dự đoán hành vi người tiêu dùng. Tuy nhiên, phần lớn các công trình tập trung vào dữ liệu thực tế quy mô lớn hoặc kỹ thuật mô hình phức tạp. Nghiên cứu này đóng góp bằng cách thử nghiệm một mô hình đơn giản – cây quyết định – trên tập dữ liệu mô phỏng nhằm đánh giá khả năng áp dụng trong điều kiện dữ liệu hạn chế và dễ tiếp cận với người học mới.
3. Phương pháp và công cụ nghiên cứu
Phương pháp nghiên cứu thực nghiệm (Experimental Research) được sử dụng nhằm kiểm tra mối quan hệ nhân quả giữa các biến dựa vào chương trình máy học thông qua các thực nghiệm có kiểm soát. Công cụ được sử dụng, là các phần mềm Anacona, Jupyter, VS code và một vài phần mềm khác. Bài viết bắt đầu bằng việc giới thiệu các khái niệm về hành vi người tiêu dùng và máy học. Trong nghiên cứu này, mô hình học có giám sát được sử dụng là cây quyết định (Decision Tree Classifier), thuộc thư viện scikit – learn của Python. Đây là mô hình phân loại phổ biến, hoạt động bằng cách chia dữ liệu thành các nhánh dựa trên tiêu chí thông tin nhằm tối đa hóa độ thuần khiết của tập con tại mỗi nút.
Cấu hình mô hình sử dụng như sau:
– criterion = ‘gini’: dùng chỉ số Gini để đo độ thuần khiết.
– max_depth = None: không giới hạn độ sâu của cây.
– min_samples_split = 2: tối thiểu hai mẫu để chia tiếp một nhánh.
– random_state = 42: bảo đảm kết quả có thể tái lập.
Sau khi huấn luyện mô hình với tập huấn luyện, kết quả được đánh giá trên tập test dựa trên nhiều chỉ số đánh giá khác nhau.
Các chỉ số đánh giá hiệu suất mô hình bao gồm:
– Độ chính xác (Accuracy): tỷ lệ dự đoán đúng trên tổng số dự đoán, trong đó: Accuracy = Số dự đoán đúng/Tổng số mẫu
– Độ chính xác theo lớp (Precision): tỷ lệ mẫu được gán đúng vào một lớp trên tổng số mẫu mô hình đã gán vào lớp đó.
– Khả năng thu hồi (Recall): tỷ lệ mẫu đúng của một lớp được mô hình dự đoán đúng.
– F1-score: trung bình điều hòa giữa Precision và Recall, đặc biệt hữu ích khi dữ liệu bị lệch lớp. F1-score = 2 * Precision * Recall / (Precision + Recall).
– Ma trận nhầm lẫn (Confusion Matrix): cho biết số lượng dự đoán đúng/sai theo từng lớp, từ đó phát hiện được thiên lệch của mô hình nếu có.
Tất cả các chỉ số này được tính bằng các hàm classification_report và confusion_matrix trong thư viện sklearn.metrics.
4. Cách thức xây dựng mô hình máy học
Trước khi đề cập đến việc xây dựng mô hình máy học, các khái niệm liên quan được sử dụng sẽ phải cần làm rõ.
Hành vi người tiêu dùng là các hành động và quyết định mà cá nhân hoặc hộ gia đình thực hiện khi họ chọn, mua, sử dụng và loại bỏ một sản phẩm hoặc dịch vụ. Nhiều yếu tố tâm lý, xã hội học và văn hóa đóng vai trò quan trọng trong cách người tiêu dùng tương tác với thị trường. Việc phân tích hành vi người tiêu dùng giúp chúng ta hiểu cũng như giúp trả lời các câu hỏi nghiên cứu. Cuối cùng, muốn ghi lại một số hành vi nhất định để sử dụng trong tương lai, mục đích làm bằng chứng hoặc hiện tại chưa rõ thông tin được sử dụng như thế nào nhưng có thể hữu ích về sau. Dựa trên thông tin được lưu trữ, sẽ thu được kiến thức mới trong tương lai và được sử dụng để đưa ra quyết định/hành động.
Máy học (học máy) là một lĩnh vực của trí tuệ nhân tạo (AI) liên quan đến việc nghiên cứu và xây dựng các mô hình cho phép các hệ thống học tự động từ dữ liệu đầu vào để giải quyết một vấn đề cụ thể. Các thuật toán máy học xây dựng nên một mô hình dựa trên dữ liệu mẫu, được gọi là dữ liệu huấn luyện, để đưa ra dự đoán hoặc quyết định mà không cần lập trình chi tiết về việc đưa ra dự đoán hoặc quyết định này. Theo IMB, máy học là một nhánh của khoa học máy tính tập trung vào việc sử dụng dữ liệu và thuật toán để cho phép bắt chước con người học hỏi, dần dần cải thiện độ chính xác của nó.
Cách thức xây dựng mô hình, với dữ liệu đầu vào được thu thập ngẫu nhiên, mô hình máy học sẽ được xây dựng trải qua 7 bước:
Bước 1: Thu thập dữ liệu
Bước 2: Làm sạch dữ liệu
Bước 3: Chia dữ liệu là 2 phần, 1 phần dùng để huấn luyện, 1 phần dùng để kiểm tra
Bước 4: Tạo ra mô hình
Bước 5: Huấn luyện mô hình
Bước 6: Đưa ra dự đoán
Bước 7: Đánh giá và cải thiện mô hình
Để xây dựng mô hình máy học, có nhiều chọn lựa, vì mô hình máy học rất đa dạng, tùy theo nhu cầu, tính chất, ngữ cảnh … chúng ta sẽ chọn mô hình nào cho phù hợp. Dưới đây có thể liệt kê ra một số mô hình máy học hiện đang được áp dụng: học có giám sát, bao gồm hồi quy và phân loại; học không giám sát, bao gồm phân cụm và giảm chiều dữ liệu; học bán giám sát; học tăng cường; các mô hình dựa trên mạng nơ-ron.
Do bài viết mang tính chất đề xuất, nên tác giả sẽ chọn một mô hình đơn giản nhất có thể để viết, đó là phân loại trong học có giám sát. Bộ dữ liệu được sử dụng trong nghiên cứu là dữ liệu mô phỏng (synthetic data) do tác giả tự xây dựng nhằm mô phỏng hành vi tiêu dùng đơn giản. Tập dữ liệu bao gồm 18 dòng, mỗi dòng đại diện cho một cá nhân với ba thuộc tính: tuổi, giới tính và thể loại âm nhạc yêu thích. Đây là các đặc trưng nhân khẩu học phổ biến trong nghiên cứu hành vi người tiêu dùng. Mặc dù không phải dữ liệu thu thập thực tế, dữ liệu mô phỏng vẫn được thiết kế có tính đại diện và phân bố đều giữa các nhóm giới tính, độ tuổi và thể loại âm nhạc. Trước khi đưa vào mô hình học máy, dữ liệu được xử lý theo các bước sau:
– Mã hóa nhãn (Label Encoding): giới tính (“Nam”, “Nữ”) và thể loại âm nhạc (Jazz, Rock, EDM…) được chuyển thành các giá trị số nguyên để mô hình có thể xử lý.
– Kiểm tra dữ liệu thiếu: do dữ liệu được tạo có kiểm soát, không có trường nào bị thiếu (missing value).
– Không thực hiện chuẩn hóa (normalization) vì các biến đầu vào đều là định tính rời rạc hoặc số nguyên nhỏ, không cần biến đổi về cùng một thang đo.
– Chia dữ liệu huấn luyện và kiểm tra theo các tỷ lệ khác nhau (80/20, 60/40, 20/80) để đánh giá ảnh hưởng của lượng dữ liệu đến hiệu quả mô hình.
Bước 1: Thu thập dữ liệu.
Bảng dữ liệu mô phỏng được xây dựng như Bảng 1:
Bảng 1: Tập dữ liệu mô phỏng (Nam = 1, Nữ = 0)
| No. (STT) | Age (Tuổi) | Gender (Giới tính) | Genre (Thể loại) |
| 1 | 20 | 1 | HipHop |
| 2 | 23 | 1 | HipHop |
| 3 | 25 | 1 | HipHop |
| 4 | 26 | 1 | Jazz |
| 5 | 29 | 1 | Jazz |
| 6 | 30 | 1 | Jazz |
| 7 | 31 | 1 | Classical |
| 8 | 33 | 1 | Classical |
| 9 | 37 | 1 | Classical |
| 10 | 20 | 0 | Dance |
| 11 | 21 | 0 | Dance |
| 12 | 25 | 0 | Dance |
| 13 | 26 | 0 | Acoustic |
| 14 | 27 | 0 | Acoustic |
| 15 | 30 | 0 | Acoustic |
| 16 | 31 | 0 | Classical |
| 17 | 34 | 0 | Classical |
| 18 | 35 | 0 | Classical |
Bước 2: Làm sạch dữ liệu
Làm sạch dữ liệu là quá trình xử lý và chuẩn bị dữ liệu thô để nó trở nên chính xác, nhất quán và dễ sử dụng cho phân tích hoặc mô hình hóa. Dữ liệu thường không hoàn hảo khi bạn thu nhập nó, có thể chứa các lỗi, dữ liệu thiếu, giá trị không hợp lệ, trùng lặp hoặc không đúng định dạng. Quá trình làm sạch dữ liệu sẽ loại bỏ hoặc khắc phục những vấn đề này.
Bước 3: Chia dữ liệu làm hai phần, một phần dùng để huấn luyện, một phần dùng để kiểm tra
Dữ liệu thu thập từ bước một được chia làm hai phần, tỷ lệ phân chia sẽ ảnh hưởng đến độ chính xác của kết quả đầu ra. Nếu 80% dữ liệu dùng để huấn luyện, 20% dùng để kiểm tra, độ chính xác có thể trên 70%. Ngược lại, 20% dữ liệu dùng để huấn luyện, 80% dùng để kiểm tra, độ chính xác sẽ giảm còn khoảng dưới 40%.
Bước 4: Xây dựng mô hình máy học
Để sử dụng mô hình máy học, có 4 công đoạn chính:
Công đoạn thứ nhất, nhập các thư viện, các module và các hàm được xây dựng sẵn trong ngôn ngữ lập trình Python.
Công đoạn thứ hai, đọc file dữ liệu đã được thu thập từ bước 1. Chia dữ liệu ra làm loại, dữ liệu đầu vào và dữ liệu đầu ra.
Bước 5: Huấn luyện mô hình
Công đoạn 3: huấn luyện mô hình
Phương thức .fit() được lấy từ thư viện Scikit-learn là một hàm dùng để huấn luyện mô hình. Phương thức .fit() nhận hai tham số đầu vào, bao gồm:
– Dữ liệu đầu vào (X – train).
– Dữ liệu đầu ra (y – train)
Bước 6: Đưa ra kết quả dự đoán
Công đoạn 4: Dự đoán kết quả.
Khi cung cấp dữ liệu đầu vào bao gồm tuổi và giới tính, biến predictions sẽ trả cho ta kết quả đầu ra.
Bước 7: Đánh giá kết quả dự đoán và cải thiện mô hình
Với kết quả đầu ra ở bước 6, làm thế nào để đánh giá mô hình cho ra kết quả có chính xác không và tỷ lệ chính xác đó là bao nhiêu? Nếu chạy với lệnh này, giá trị đầu ra sẽ thay đổi từ 0 đến 1 (0 tức là 0% và 1 tức là 100% về độ chính xác).
Do dữ liệu được chia ngẫu nhiên, kết quả có thể thay đổi nhẹ giữa các lần chạy, mặc dù tỷ lệ chọn vẫn luôn là 80% nên kết quả trả về là khác nhau. Khi tham số testsize được điều chỉnh lên 0.8, tỷ lệ chính xác có thể giảm xuống mức 20 – 40% khi tập huấn luyện chỉ chiếm 20% dữ liệu. Do chỉ có 20% giá trị trong tập dữ liệu được dùng để huấn luyện – tỷ lệ chính xác giảm mạnh – còn 80% dùng để kiểm tra. Tuy nhiên, không cần thiết phải tái huấn luyện mô hình, vì mô hình đã có thể được lưu và sử dụng lại. Để sử dụng mô hình, chỉ cần huấn luyện một lần và được sử dụng cho các lần sau đó. Việc này được thực hiện bằng cách là sau khi huấn luyện, người ta lưu mô hình vào một đối tượng, sau này, khi có nhu cầu sử dụng, chỉ cần tải xuống.
5. Kết quả nghiên cứu
Kết quả nghiên cứu được chia ra làm 2 bảng, một bảng dành cho dự đoán kết quả đầu ra và một bảng dành cho tính chính xác. Ở bảng dự đoán kết quả đầu ra, sẽ chọn những đối tượng không nằm trong cơ sở dữ liệu để dự đoán.
Bảng 2: Dự đoán kết quả đầu ra
| No. (Số thứ tự) | Age (Tuổi) | Gender (Giới tính) | Genre (Thể loại) |
| 1 | 21 | 1 | HipHop |
| 2 | 22 | 0 | Dance |
| 3 | 28 | 1 | Jazz |
| 4 | 28 | 0 | Acoustic |
| 5 | 34 | 1 | Classical |
Bảng 3: Độ chính xác của kết quả đầu ra
| No. (Số thứ tự) | % dữ liệu huấn luyện (%) | % dữ liệu kiểm tra (%) | Accuracy độ chính xác |
| 1 | 80 | 20 | 0.7 – 1 |
| 2 | 70 | 30 | 0.6 – 0.8 |
| 3 | 60 | 40 | 0.5 – 0.8 |
| 4 | 40 | 60 | 0.4 – 0.7 |
| 5 | 20 | 80 | 0.2 – 0.6 |
6. Thảo luận
Hình 2 trình bày làm thế nào mô hình (model) đưa ra quyết định. Mỗi ô ở trên tương ứng với một “nút” (node), dưới mỗi nút luôn có hai nút con. Nếu điều kiện là “true” thì sẽ đi theo nhánh bên trái và ngược lại. Điều kiện ở đây là dòng đầu tiên trong mỗi nút (ví dụ, tuổi nhỏ hơn 30,5).
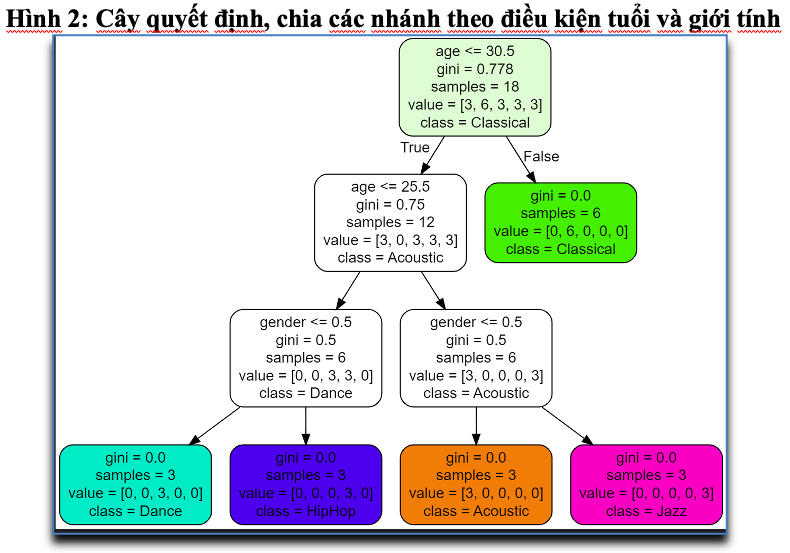
Chỉ số Gini trong hình trên là một thước đo dùng trong thuật toán cây quyết định (Decision Tree) để đánh giá mức độ hỗn loạn hay không đồng nhất của dữ liệu tại một nút. Nó phản ánh độ phân tán của các nhãn trong tập dữ liệu tại nút đó. Trong mô hình cây quyết định, thuật toán tìm cách phân chia dữ liệu sao cho giảm thiểu chỉ số Gini càng nhiều càng tốt sau mỗi bước chia tách nhằm đạt được các nút có chỉ số Gini bằng không hoặc gần bằng không, biểu thị sự phân loại chính xác.
Như vậy, cùng dữ liệu đầu vào, nếu sử dụng phần mềm SPSS và máy học để phân tích sẽ có một số điểm khác biệt cụ thể. Theo đó, để kiểm tra xem có mối liên hệ thống kê giữa giới tính và thể loại nhạc yêu thích hay không, nghiên cứu thực hiện kiểm định Chi-square với bảng tần số chéo như Bảng 4.
Bảng 4: Kiểm định Chi-square
| Giới tính | Jazz | Rock | EDM | Tổng |
| Nam | 3 | 1 | 2 | 6 |
| Nữ | 2 | 3 | 1 | 6 |
| Tổng | 5 | 4 | 3 | 12 |
Áp dụng kiểm định Chi-square với giả thuyết:
H0: Không có mối liên hệ giữa giới tính và thể loại nhạc yêu thích.
H1: Có mối liên hệ giữa giới tính và thể loại nhạc yêu thích.
Kết quả kiểm định (thực hiện bằng Python – scipy.stats.chi2_contingency): Chi-square statistic = 2.50; Degrees of freedom = 2; p-value = 0.286. Với p-value > 0.05, ta không đủ bằng chứng để bác bỏ giả thuyết H0. Điều này có nghĩa là chưa thể kết luận có mối liên hệ thống kê giữa giới tính và thể loại nhạc yêu thích trong tập dữ liệu mô phỏng nhỏ này.
7. Ứng dụng của máy học
Trên cơ sở kết quả nghiên cứu có thể thấy, ứng dụng của máy học trong nghiên cứu hành vi người tiêu dùng rất đa dạng và có thể mang lại nhiều lợi ích cho các doanh nghiệp trong việc hiểu rõ nhu cầu, sở thích và thói quen mua sắm của khách hàng. Một số ứng dụng chính bao gồm:
– Phân tích và dự đoán xu hướng mua sắm: máy học giúp phân tích các dữ liệu lịch sử về hành vi mua sắm, từ đó dự đoán xu hướng và nhu cầu trong tương lai. Các mô hình này có thể dự báo sản phẩm nào sẽ bán chạy, mùa cao điểm cho từng mặt hàng, hay xu hướng tiêu dùng của khách hàng.
– Phân khúc khách hàng: dựa trên các thuật toán phân cụm (clustering), máy học có thể chia khách hàng thành các nhóm khác nhau dựa trên sở thích, hành vi hoặc nhân khẩu học. Điều này giúp doanh nghiệp tạo ra các chiến lược tiếp thị phù hợp cho từng nhóm khách hàng cụ thể.
– Cá nhân hóa trải nghiệm khách hàng: dựa trên hành vi duyệt web, lịch sử mua sắm và dữ liệu khác, máy học giúp xây dựng các hệ thống gợi ý sản phẩm phù hợp với từng người dùng. Ví dụ, các nền tảng như Amazon và Netflix sử dụng máy học để đề xuất sản phẩm hoặc nội dung phù hợp với sở thích của từng cá nhân.
– Phân tích cảm xúc và phản hồi khách hàng: các mô hình máy học có thể phân tích các nhận xét, đánh giá và bình luận của khách hàng trên mạng xã hội, website và các nền tảng khác để hiểu được cảm xúc và quan điểm của khách hàng đối với sản phẩm hay dịch vụ. Từ đó, doanh nghiệp có thể điều chỉnh sản phẩm, dịch vụ để cải thiện trải nghiệm khách hàng.
– Dự đoán tỷ lệ rời bỏ khách hàng: máy học giúp xác định những khách hàng có khả năng rời bỏ dịch vụ trong tương lai. Bằng cách phát hiện sớm các dấu hiệu rời bỏ, doanh nghiệp có thể đưa ra các chương trình ưu đãi hoặc chăm sóc đặc biệt để giữ chân khách hàng.
– Định giá động: máy học giúp điều chỉnh giá sản phẩm dựa trên nhu cầu thị trường, cạnh tranh và lịch sử giá cả. Điều này giúp doanh nghiệp tối ưu hóa lợi nhuận và tăng khả năng cạnh tranh.
– Tối ưu hóa chiến dịch tiếp thị: bằng cách phân tích dữ liệu lớn từ các chiến dịch tiếp thị trước đó, máy học có thể xác định yếu tố nào mang lại hiệu quả cao nhất, tối ưu hóa ngân sách quảng cáo, kênh quảng cáo và thời gian chạy chiến dịch để đạt được hiệu quả tối đa.
Nhờ những ứng dụng này, máy học hỗ trợ doanh nghiệp hiểu sâu hơn về hành vi của người tiêu dùng và đưa ra quyết định kinh doanh hiệu quả hơn.
8. Kết luận
Sử dụng mô hình máy học, có thể dự đoán được hành vi của người tiêu dùng. Kết quả dự đoán này chính xác hoặc không tùy thuộc vào tập dữ liệu đầu vào cung cấp, nếu tỷ lệ tập dữ liệu thu thập được càng lớn tính chính xác càng lớn và ngược lại. Bên cạnh đó, tỷ lệ giữa tập huấn luyện và tập kiểm tra trong tập dữ liệu đầu vào cũng là một yếu tố quyết định tính chính xác trong kết quả dự đoán. Nếu tỷ lệ tập huấn luyện càng lớn, tính chính xác sẽ càng cao và ngược lại.
So với phần mềm SPSS, mô hình máy học cho phép tự động hóa quá trình dự đoán, loại bỏ sự phụ thuộc vào diễn giải thủ công từ phía người thực hiện. Với phần mềm SPSS, sau khi có số liệu thống kê đầu ra theo mô hình đã chọn, người thực hiện phải diễn giải theo kết quả mô hình đưa ra. Máy học mang lại nhiều ứng dụng cụ thể trong việc phân tích hành vi người tiêu dùng, từ cá nhân hóa, nhóm hóa xu hướng thị trường, giúp doanh nghiệp đưa ra những hành động/quyết định cụ thể cho từng giai đoạn, không có kiểu cứng nhắc như các phương pháp phân tích khác do cần thời gian cho sự can thiệp của con người.
Tài liệu tham khảo:
1. Liu, B. (2012). Sentiment Analysis and Opinion Mining. Synthesis Lectures on Human Language Technologies.
2. Jain, A., & Singh, B. (2018). Consumer behavior analysis using decision tree algorithm. International Journal of Computer Applications.
3. Chen, Y., Zhang, L., & Wang, G. (2020). A survey on decision tree algorithm for machine learning. Journal of Artificial Intelligence Research.
4. Sahu, T. K., & Singh, A. (2022). Role of machine learning in understanding consumer preferences: A review. Journal of Retailing and Consumer Services.
5. Huang, T., & Li, X. (2021). Predicting online consumer behavior using ensemble learning. Expert Systems with Applications.
6. Han, J., Pei, J., & Kamber, M. (2011). Data Mining: Concepts and Techniques (3rd ed.). Elsevier.
7. Zhang, Z. (2019). Machine Learning Fundamentals. Springer.



