
TS. Đặng Thị Hồng Hà
Trường Kinh tế, Đại học Công nghiệp Hà Nội
Đỗ Thị Hoài
Sinh viên Đại học Công nghiệp Hà Nội
(Quanlynhanuoc.vn) – Trong những năm gần đây, gian lận trong hoạt động thanh toán tại các ngân hàng Việt Nam có xu hướng gia tăng cả về số lượng lẫn mức độ tinh vi. Học máy – một nhánh nổi bật của trí tuệ nhân tạo đang được xem là hướng đi đầy tiềm năng trong việc nâng cao hiệu quả phát hiện gian lận. Không giống như các hệ thống kiểm soát truyền thống, các mô hình học máy có thể phát hiện ra những dấu hiệu bất thường dù rất nhỏ và hiếm gặp, từ đó cảnh báo sớm các hành vi gian lận với độ chính xác cao hơn. Bài viết khai thác và phân tích dữ liệu từ bộ dữ liệu “Fraud Detection on Bank Payments”, áp dụng các thuật toán học máy, như: Logistic Regression, Random Forest, K-Nearest Neighbors (KNN) và XGBoost để xây dựng mô hình phát hiện gian lận. Kết quả cho thấy, mô hình XGBoost cho hiệu suất vượt trội nhất bảo đảm khả năng phát hiện gian lận với tỷ lệ bỏ sót thấp. Random Forest cũng cho kết quả về tính ổn định và khả năng xử lý dữ liệu mất cân bằng. Trong khi đó, Logistic Regression và KNN cho kết quả khiêm tốn hơn, song vẫn hữu ích cho phân tích tham chiếu hoặc triển khai mô hình đơn giản.
Từ khóa: Mô hình học máy; phát hiện, gian lận thanh toán; ngân hàng.
1. Đặt vấn đề
Các ngân hàng đang trong quá trình chuyển đổi số mạnh mẽ nhằm thích ứng với nhu cầu ngày càng cao của khách hàng về sự tiện lợi, nhanh chóng và an toàn trong giao dịch. Những hình thức thanh toán hiện đại như Internet Banking, Mobile Banking, ví điện tử hay chuyển khoản trực tuyến đã dần thay thế các phương thức giao dịch truyền thống. Tuy nhiên, sự phát triển nhanh chóng của công nghệ trong ngành tài chính cũng kéo theo một vấn đề đáng lo ngại: gian lận thanh toán đang trở nên tinh vi, phức tạp và khó kiểm soát hơn bao giờ hết.
Trong khi đó, các hệ thống phát hiện gian lận truyền thống thường hoạt động dựa trên các quy tắc cứng nhắc, được xây dựng thủ công từ kinh nghiệm thực tiễn. Dù những quy tắc này có thể hiệu quả ở một mức độ nhất định, nhưng chúng rất khó thích ứng khi các hành vi gian lận liên tục thay đổi. Các đối tượng gian lận ngày nay không còn sử dụng các chiêu trò đơn giản mà thường che giấu rất khéo léo trong hàng triệu giao dịch hợp lệ, khiến việc phát hiện gian lận theo cách thông thường ngày càng khó khăn và kém hiệu quả.
Trong bối cảnh đó, học máy đang được xem là một hướng đi đầy hứa hẹn. Điểm mạnh của học máy là khả năng học từ dữ liệu lịch sử, tự động nhận diện những mẫu bất thường và thích nghi với những thay đổi mới mà không cần con người phải can thiệp trực tiếp. Đặc biệt trong lĩnh vực ngân hàng – nơi dữ liệu giao dịch rất lớn và liên tục, học máy có thể giúp phát hiện ra các giao dịch gian lận ngay cả khi chúng chỉ chiếm một tỷ lệ rất nhỏ nhưng gây hậu quả lớn. Không chỉ vậy, việc áp dụng các mô hình học máy còn giúp tiết kiệm thời gian, nâng cao độ chính xác và hỗ trợ ngân hàng ra quyết định nhanh chóng hơn.
Từ những lý do trên, với mục đích nghiên cứu và ứng dụng học máy vào phát hiện gian lận thanh toán trong ngân hàng, bài viết cung cấp một hướng tiếp cận hiện đại, linh hoạt và có khả năng mở rộng, giúp các ngân hàng ứng phó tốt hơn với những thách thức ngày càng lớn về an toàn giao dịch trong kỷ nguyên số.
2. Phương pháp nghiên cứu
Trong lĩnh vực ngân hàng, phát hiện gian lận thanh toán là một bài toán quan trọng nhưng đầy thách thức, bởi dữ liệu thường có sự mất cân bằng nghiêm trọng, biến động cao và khó dự đoán. Để giải quyết bài toán này, các thuật toán học máy được sử dụng nhằm tự động phát hiện các mẫu giao dịch bất thường dựa trên dữ liệu quá khứ. Dưới đây là những thuật toán học máy phổ biến nhất được áp dụng rộng rãi trong lĩnh vực này:
(1) Thuật toán hồi quy Logistic (Logistic Regression)
Hồi quy Logistic là một trong những mô hình đơn giản và dễ hiểu nhất trong học máy, thường được sử dụng như một mô hình nền tảng (baseline) để so sánh với các mô hình phức tạp hơn. Thuật toán này hoạt động tốt với bài toán phân loại nhị phân, như phân biệt giữa giao dịch gian lận và hợp lệ. Một ưu điểm nổi bật của hồi quy Logistic là khả năng giải thích được mô hình thông qua các hệ số hồi quy, điều này đặc biệt có ích trong lĩnh vực ngân hàng – nơi tính minh bạch và khả năng kiểm toán là rất quan trọng. Tuy nhiên, do là một mô hình tuyến tính, Logistic Regression khó có thể nắm bắt các mối quan hệ phi tuyến phức tạp giữa các đặc trưng và thường không hiệu quả trong các tập dữ liệu có tính mất cân bằng cao nếu không có biện pháp điều chỉnh như gán trọng số hay oversampling.
(2) Cây quyết định và rừng ngẫu nhiên (Decision Tree & Random Forest)
Cây quyết định (Decision Tree) là mô hình học có cấu trúc dạng phân nhánh, giúp đưa ra quyết định dựa trên việc chia nhỏ dữ liệu thành các tập con dựa trên giá trị của các đặc trưng. Dù đơn giản và dễ hiểu, cây quyết định đơn lẻ thường dễ bị overfitting. Để khắc phục nhược điểm này, Random Forest ra đời như một phương pháp ensemble learning, kết hợp nhiều cây quyết định khác nhau được huấn luyện trên các tập con dữ liệu ngẫu nhiên. Mô hình này có khả năng học phi tuyến, kháng nhiễu tốt và cung cấp thông tin giá trị về độ quan trọng của các đặc trưng (feature importance). Trong bài toán phát hiện gian lận, Random Forest thường mang lại độ chính xác cao và khả năng khái quát tốt, dù thời gian huấn luyện và suy luận có thể dài hơn.
(3) Thuật toán tăng cường XGBoost (Extreme Gradient Boosting)
XGBoost là một trong những thuật toán tăng cường (boosting) mạnh mẽ và hiệu quả nhất hiện nay. Nó hoạt động bằng cách huấn luyện các mô hình yếu liên tiếp nhau, trong đó mỗi mô hình mới học từ lỗi của mô hình trước đó. XGBoost đặc biệt được ưa chuộng trong các cuộc thi về khoa học dữ liệu vì hiệu suất cao, khả năng kiểm soát overfitting thông qua regularization và tính linh hoạt khi xử lý các loại dữ liệu khác nhau. Trong bối cảnh phát hiện gian lận – nơi sự chênh lệch giữa tỷ lệ giao dịch hợp lệ và gian lận là rất lớn – XGBoost tỏ ra đặc biệt hiệu quả nhờ khả năng tối ưu loss function một cách linh hoạt. Tuy nhiên, mô hình này đòi hỏi điều chỉnh nhiều tham số và có thể tiêu tốn tài nguyên nếu dữ liệu quá lớn.
(4) Thuật toán K-Nearest Neighbors (KNN)
KNN là một thuật toán đơn giản nhưng trực quan, dựa trên nguyên lý khoảng cách: một điểm dữ liệu mới sẽ được gán nhãn dựa trên nhãn phổ biến nhất của “k hàng xóm” gần nhất trong không gian đặc trưng. Mặc dù dễ cài đặt và không cần quá trình huấn luyện phức tạp, KNN lại gặp nhiều khó khăn trong xử lý dữ liệu lớn, do phải tính toán khoảng cách với tất cả điểm trong tập huấn luyện. Hơn nữa, KNN rất nhạy cảm với nhiễu và dữ liệu dư thừa, và đặc biệt không phù hợp với dữ liệu mất cân bằng – vì các giao dịch gian lận (ít ỏi) thường bị “chìm” trong số lượng lớn giao dịch hợp lệ.
Dữ liệu được sử dụng trong nghiên cứu được lấy từ bộ dữ liệu công khai có tên “Fraud Detection on Bank Payments” trên nền tảng Kaggle, được chia sẻ bởi tác giả Turkayavci. Đây là một bộ dữ liệu tổng hợp mô phỏng hoạt động giao dịch trong một hệ thống ngân hàng điện tử, với quy mô hơn 6 triệu giao dịch, diễn ra liên tục trong vòng 30 ngày.
Bộ dữ liệu bao gồm 10 biến đầu vào (features) và 1 nhãn đầu ra (label). Mỗi giao dịch được mô tả thông qua các trường sau:
Bảng 1. Mô tả đặc trưng của bộ dữ liệu
| Tên biến | Kiểu dữ liệu | Mô tả |
| Step | Số nguyên | Số thời gian (mỗi bước ~ 1 giờ), phản ánh thời điểm giao dịch |
| Type | Danh mục | Loại giao dịch: PAYMENT, TRANSFER, CASH_OUT, DEBIT, CASH_IN |
| Amount | Số thực | Số tiền của giao dịch |
| NameOrig | Chuỗi | Mã định danh tài khoản gửi tiền |
| OldbalanceOrig | Số thực | Số dư ban đầu của tài khoản gửi |
| NewbalanceOrig | Số thực | Số dư sau giao dịch của tài khoản gửi |
| NameDest | Chuỗi | Mã định danh tài khoản nhận tiền |
| OldbalanceDest | Số thực | Số dư ban đầu của tài khoản nhận |
| NewbalanceDest | Số thực | Số dư sau giao dịch của tài khoản nhận |
| IsFlaggedFraud | Nhị phân (0/1) | Đánh dấu giao dịch bị hệ thống nghi ngờ là gian lận (nhưng không đồng nghĩa với chắc chắn) |
| IsFraud | Nhị phân (0/1) | Nhãn thực tế – giao dịch có phải gian lận hay không (1 = fraud, 0 = không fraud) |
3. Kết quả nghiên cứu
3.1. Mô hình hồi quy Logistic
Hồi quy logistic được triển khai như một mô hình nền tảng nhằm kiểm tra khả năng phân loại giao dịch gian lận và không gian lận sau khi dữ liệu đã được cân bằng bằng kỹ thuật SMOTE. Mô hình được huấn luyện với tập huấn luyện X_train, y_train và đánh giá trên tập kiểm tra X_test, y_test. Kết quả đánh giá mô hình được thể hiện thông qua bảng hình sau.
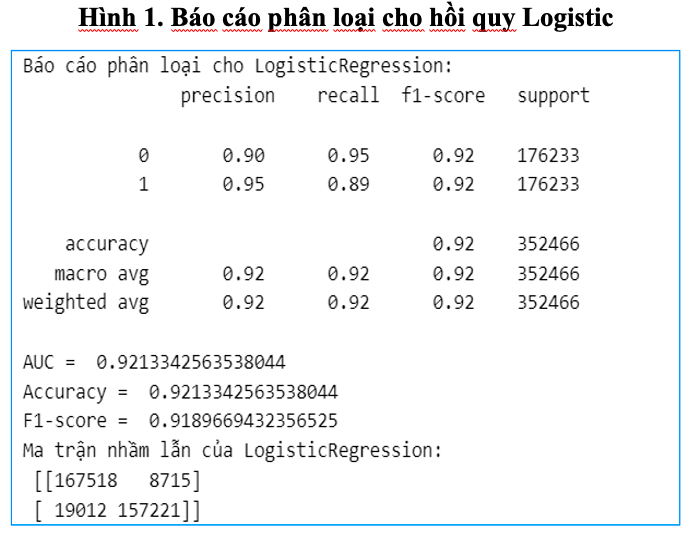
Từ kết quả trên cho thấy, Accuracy đạt 92.13%, cho thấy mô hình phân loại chính xác hơn 92% tổng số giao dịch (cả gian lận và không gian lận). Đây là một kết quả khá tốt, đặc biệt là trong bối cảnh phát hiện gian lận – một bài toán vốn rất khó do tính chất mất cân bằng của dữ liệu ban đầu. Precision của lớp gian lận (1) là 0.95, nghĩa là trong số các giao dịch mà mô hình dự đoán là gian lận, có đến 95% là đúng. Điều này rất quan trọng trong thực tế, vì một tỷ lệ dương tính giả cao có thể gây phiền hà cho khách hàng.
Biểu đồ ROC cho thấy, đường cong nằm cao rõ rệt so với đường chéo ngẫu nhiên. Chỉ số AUC đạt 0.97, một kết quả rất ấn tượng trong bài toán có dữ liệu mất cân bằng như phát hiện gian lận. AUC cao cho thấy, mô hình có khả năng phân biệt mạnh giữa giao dịch gian lận và không gian lận, bất kể ngưỡng phân loại.
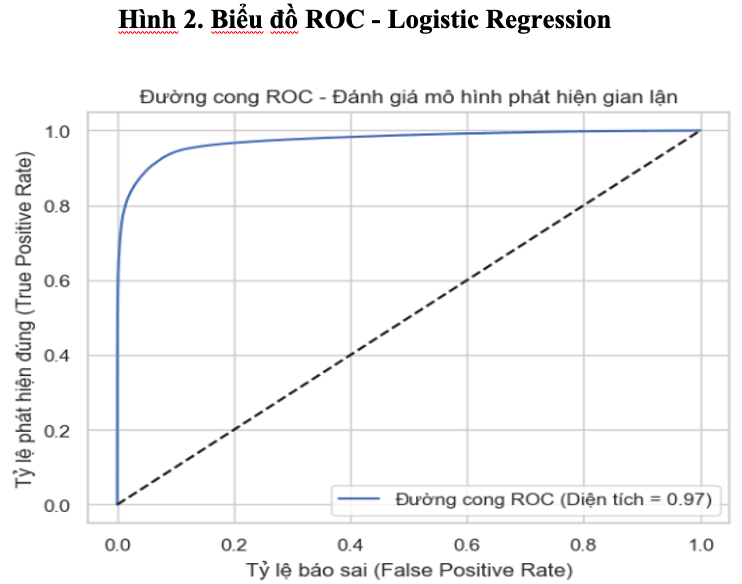
Mặc dù là một thuật toán tuyến tính đơn giản, hồi quy logistic đã chứng minh được hiệu quả rõ rệt trong bài toán phát hiện gian lận. Với Accuracy đạt 92.13%, AUC = 0.97 và F1-score xấp xỉ 0.92, mô hình đủ mạnh để làm chuẩn so sánh với các mô hình học máy phức tạp hơn. Quan trọng hơn, các chỉ số recall và precision cho lớp gian lận đều vượt mức kỳ vọng, thể hiện sự phù hợp của mô hình trong việc hỗ trợ ngân hàng sàng lọc rủi ro giao dịch.
3.2. Mô hình K-Nearest Neighbors (KNN)
Mô hình KNN được huấn luyện với tham số n_neighbors = 5 (sử dụng 5 hàng xóm gần nhất) và p = 1 (dùng khoảng cách Manhattan), để phân loại các giao dịch là gian lận hay không gian lận sau khi dữ liệu đã được cân bằng bằng kỹ thuật SMOTE. Kết quả mô hình KNN thể hiện ở hình sau.
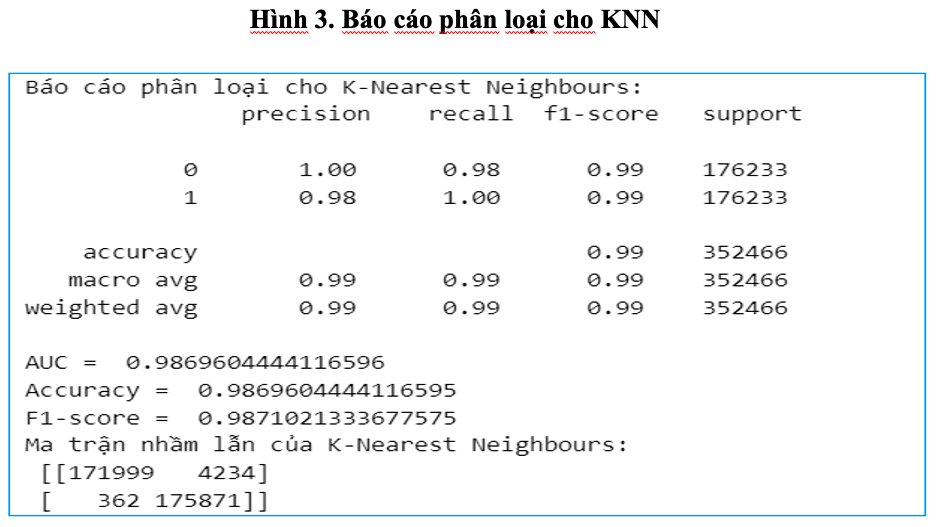
Kết quả từ hình trên cho thấy, Precision của lớp gian lận đạt 0.98, cho thấy 98% trong số các giao dịch được mô hình xác định là gian lận thực sự là gian lận. Recall đạt 1.00 với lớp gian lận – nghĩa là mô hình phát hiện 100% giao dịch gian lận thực sự, không bỏ sót trường hợp nào. F1-score đạt 0.99 cho cả hai lớp – phản ánh sự cân bằng tối ưu giữa precision và recall. Accuracy tổng thể đạt 98.7%, cao nhất trong các mô hình được triển khai đến thời điểm này. Biểu đồ đường cong ROC được thể hình qua hình sau.
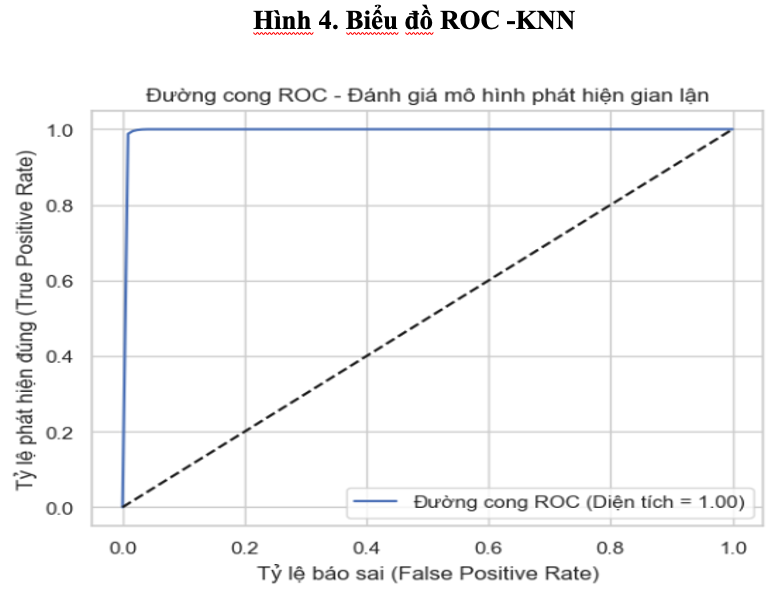
Biểu đồ ROC thể hiện đường cong chạm sát góc trên bên trái, cho thấy True Positive Rate (TPR) cao và False Positive Rate (FPR) gần như bằng 0. Diện tích dưới đường cong (AUC) đạt 1.00 tuyệt đối – một con số lý tưởng trong đánh giá mô hình phân loại nhị phân. AUC = 1.00 cho thấy mô hình có khả năng phân biệt hoàn hảo giữa giao dịch gian lận và không gian lận. Đường cong hoàn hảo này xác nhận rằng mô hình có thể hoạt động tốt ở mọi ngưỡng phân loại – điều rất hữu ích nếu cần điều chỉnh độ nhạy trong môi trường vận hành thực tế.
Mô hình KNN trong nghiên cứu đạt được hiệu suất rất ấn tượng, kết quả cho thấy đây là một mô hình có tiềm năng ứng dụng thực tiễn rất cao trong bài toán phát hiện gian lận tại ngân hàng. Nhờ việc sử dụng SMOTE để cân bằng dữ liệu và lựa chọn tham số phù hợp, mô hình đã phát huy tối đa khả năng phân loại của mình. Tuy nhiên, một điểm cần lưu ý là KNN có chi phí tính toán cao khi áp dụng trên tập dữ liệu lớn vì phải tính khoảng cách đến tất cả các điểm huấn luyện. Do đó, việc triển khai thực tế mô hình này cần được kết hợp với các kỹ thuật tối ưu hóa hoặc giới hạn phạm vi áp dụng.
3.3. Mô hình rừng ngẫu nhiên
Random Forest là tập hợp của nhiều cây quyết định hoạt động song song, nơi mỗi cây đóng vai trò là một chuyên gia đưa ra nhận định và kết quả cuối cùng được tổng hợp theo nguyên tắc bỏ phiếu đa số (voting), giúp tăng độ ổn định và giảm thiểu hiện tượng quá khớp (overfitting).
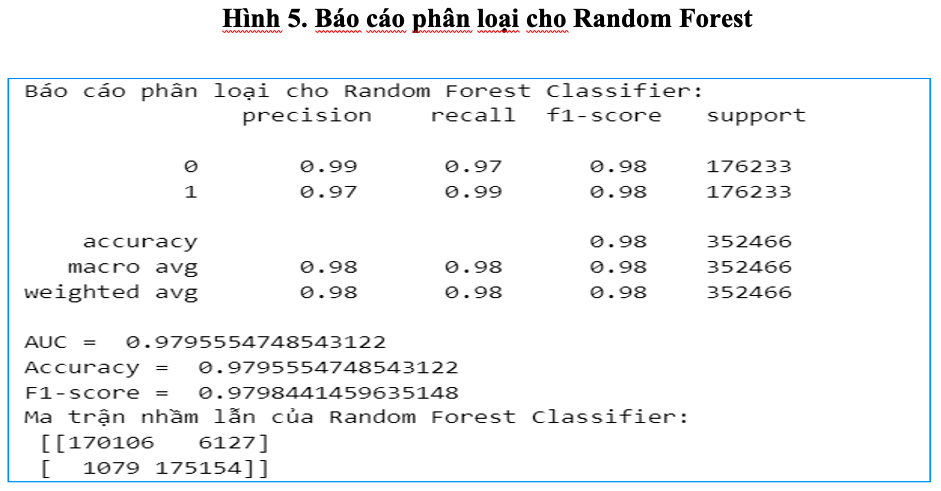
Sau quá trình huấn luyện, mô hình được đánh giá trên tập dữ liệu kiểm tra và cho thấy hiệu năng vượt trội. Độ chính xác đạt 97.96%, cho thấy mô hình đã học được đặc trưng quan trọng trong phân biệt giữa giao dịch hợp lệ và gian lận. Tuy nhiên, điều đáng chú ý hơn chính là độ chính xác này không chỉ đơn thuần cao về mặt số học mà còn mang giá trị thực tiễn nhờ khả năng phát hiện đúng đến 175.154 giao dịch gian lận trong tổng số 176.233 mẫu thuộc lớp 1, thể hiện rõ qua chỉ số Recall = 0.99 cho lớp gian lận. Điều này rất có ý nghĩa trong bối cảnh ngân hàng cần tối thiểu hóa rủi ro bỏ sót giao dịch gian lận.
Đặc biệt, đường cong ROC (Receiver Operating Characteristic) được vẽ từ xác suất dự đoán cho thấy mô hình có khả năng phân tách hai lớp gần như hoàn hảo, khi đường cong nằm sát trục phía trên bên trái đồ thị. Giá trị AUC (Area Under the Curve) đạt 0.9795, phản ánh năng lực phân biệt mạnh mẽ giữa giao dịch gian lận và không gian lận, gần tiệm cận mức lý tưởng 1.0. Trong các bài toán phân loại bất cân xứng, như: gian lận tài chính, AUC là một trong những thước đo đáng tin cậy nhất.
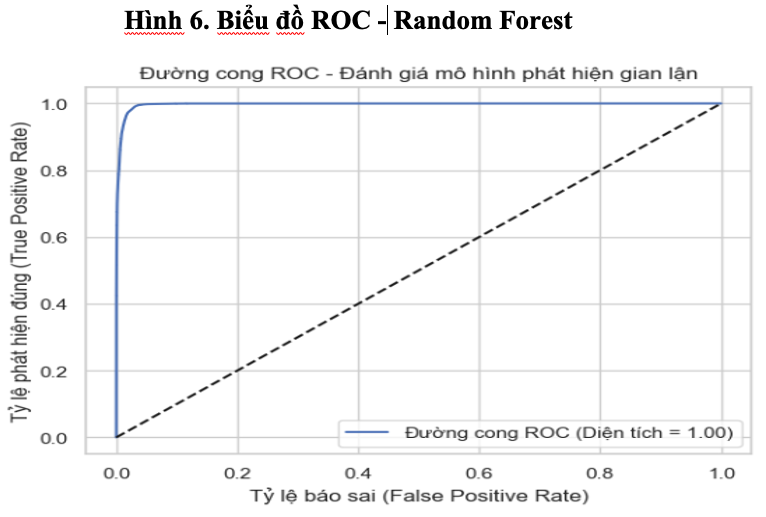
Về tổng thể, mô hình Random Forest không chỉ vượt qua các ngưỡng đánh giá cơ bản mà còn đạt được hiệu quả đáng kể trong môi trường dữ liệu tài chính thực tế. Việc kết hợp giữa các bước tiền xử lý như SMOTE, chuẩn hóa và điều chỉnh trọng số lớp giúp mô hình khai thác được toàn bộ tiềm năng của dữ liệu. Đây là bằng chứng rõ ràng về khả năng ứng dụng học máy vào phát hiện gian lận thanh toán, mang lại giá trị thiết thực cho các ngân hàng trong công tác kiểm soát rủi ro và bảo vệ hệ thống tài chính.
3.4. Mô hình XGBoost
Mô hình XGBoost được triển khai như một trong những thuật toán học máy mạnh mẽ nhất hiện nay trong lĩnh vực phân loại, đặc biệt là với các bài toán dữ liệu mất cân bằng như phát hiện gian lận giao dịch thanh toán trong ngân hàng.Dữ liệu được chia thành tập huấn luyện và tập kiểm tra sau khi đã xử lý và cân bằng bằng kỹ thuật SMOTE. Việc huấn luyện mô hình diễn ra trên tập huấn luyện X_train, y_train với bộ dữ liệu gồm hàng trăm nghìn mẫu đã chuẩn hóa và mã hóa.
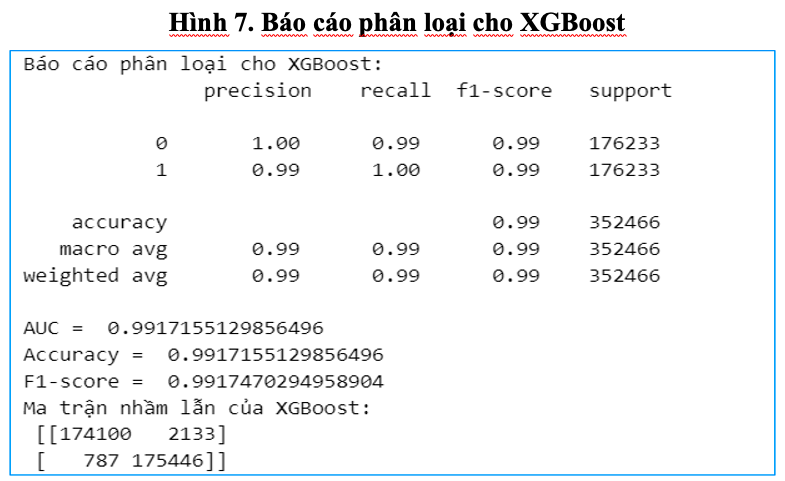
Các chỉ số đánh giá chính bao gồm Accuracy, Precision, Recall và F1-score, cho thấy mô hình đạt hiệu suất rất cao. Mô hình đạt độ chính xác lên đến 99.17%, trong số toàn bộ các giao dịch được kiểm tra, gần như tất cả đều được mô hình phân loại đúng là gian lận hoặc không gian lận. Đây là một kết quả đặc biệt ấn tượng, phản ánh mô hình đã học được rất tốt đặc điểm của cả hai loại giao dịch – một yếu tố then chốt trong hệ thống phòng chống gian lận.
Biểu đồ ROC minh họa đường cong gần như nằm sát trục trái và trần trên của đồ thị, khẳng định mô hình có năng lực phân loại xuất sắc. Giá trị AUC đạt 0.9917, chứng tỏ mô hình có khả năng phân biệt rất tốt giữa giao dịch gian lận và hợp lệ.
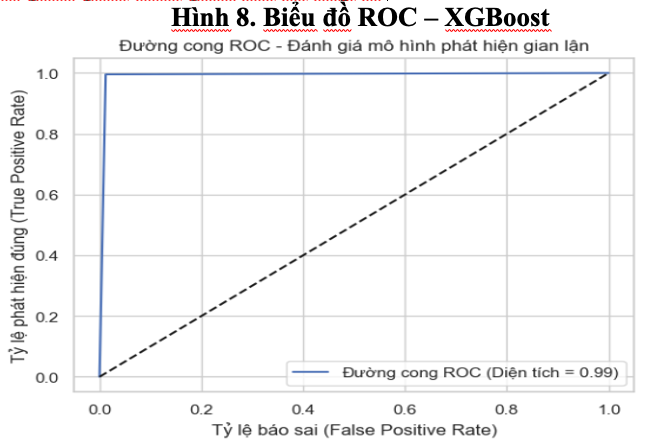
XGBoost đã chứng minh được hiệu quả vượt trội trong bài toán phát hiện gian lận thanh toán tại ngân hàng với độ chính xác và khả năng phát hiện gian lận gần như tuyệt đối. Nhờ khả năng tự động học từ lỗi của các mô hình trước, kết hợp với việc tối ưu hóa thông minh qua mỗi vòng lặp, XGBoost không những giải quyết tốt vấn đề mất cân bằng dữ liệu mà còn bảo đảm mô hình không bị overfitting. Với kết quả này, XGBoost được xem là ứng cử viên hàng đầu trong số các mô hình đã triển khai, đặc biệt phù hợp cho việc áp dụng trong hệ thống phát hiện gian lận thời gian thực tại các tổ chức tài chính và ngân hàng.
4. Kết luận và khuyến nghị
Trong quá trình nghiên cứu, đề tài đã thực hiện đầy đủ quy trình: từ thu thập và xử lý dữ liệu, đến lựa chọn, huấn luyện và đánh giá các mô hình học máy. Bốn mô hình được triển khai gồm Logistic Regression, K-Nearest Neighbors (KNN), Random Forest và XGBoost – đây là các thuật toán phổ biến, dễ triển khai nhưng mang lại hiệu quả thực tế cao nếu được sử dụng đúng cách.
Kết quả cho thấy, XGBoost là mô hình cho hiệu suất vượt trội trong phát hiện gian lận, đặc biệt trong bối cảnh dữ liệu mất cân bằng. Mô hình này thể hiện sự ổn định và khả năng nhận diện các giao dịch bất thường tốt hơn so với các thuật toán còn lại. Random Forest cũng cho kết quả khả quan, nhất là khi cần đánh giá tầm quan trọng của các đặc trưng. Ngược lại, Logistic Regression và KNN, dù đơn giản và dễ hiểu lại gặp nhiều khó khăn trong việc xử lý các mẫu dữ liệu phức tạp.
Từ những phân tích và thử nghiệm thực tế, có thể khẳng định rằng việc ứng dụng học máy vào phát hiện gian lận thanh toán là hoàn toàn khả thi và đáng đầu tư. Quan trọng hơn, nghiên cứu này không chỉ đưa ra các mô hình hiệu quả mà còn góp phần gợi mở hướng đi phù hợp cho các tổ chức tài chính trong việc hiện đại hóa hệ thống cảnh báo gian lận, từ đó bảo vệ khách hàng và nâng cao uy tín ngân hàng trong môi trường giao dịch ngày càng rủi ro.
Một trong những hạn chế đáng chú ý của nghiên cứu là việc sử dụng bộ dữ liệu công khai từ nền tảng Kaggle. Mặc dù bộ dữ liệu này được thiết kế mô phỏng theo các giao dịch thực tế trong môi trường ngân hàng, nhưng bản chất vẫn là dữ liệu giả lập, không phản ánh đầy đủ các yếu tố đặc thù về hành vi khách hàng, cơ chế bảo mật hoặc cấu trúc giao dịch nội bộ của các ngân hàng tại Việt Nam. Điều này ảnh hưởng phần nào đến tính đại diện và khả năng áp dụng trực tiếp vào môi trường thực tế. Hơn nữa, một số giao dịch gian lận trong dữ liệu có thể đã được gán nhãn sẵn, trong khi thực tế, việc phát hiện và gán nhãn gian lận thường chậm trễ hoặc bị bỏ sót.
Nghiên cứu chỉ triển khai các thuật toán học máy truyền thống, chủ yếu tập trung vào mô hình có giám sát và cấu trúc đơn giản, như: Logistic Regression, Random Forest hay XGBoost. Các kỹ thuật học sâu (Deep Learning) hiện đại như mạng nơ-ron tích chập (CNN), mạng hồi tiếp (RNN, LSTM), hay Autoencoder – vốn rất tiềm năng trong việc học đặc trưng và phát hiện hành vi bất thường phức tạp – vẫn chưa được đưa vào triển khai. Điều này làm hạn chế khả năng xử lý dữ liệu phi tuyến, dữ liệu chuỗi thời gian hoặc dữ liệu phi cấu trúc như văn bản, hình ảnh. Đồng thời, đề tài cũng chưa đi sâu vào tối ưu hóa siêu tham số (hyperparameter tuning), vốn là yếu tố quan trọng để nâng cao hiệu năng mô hình trong thực tế.
Trong tương lai, nghiên cứu có thể được mở rộng bằng cách áp dụng các phương pháp học sâu (Deep Learning) để cải thiện khả năng phát hiện gian lận trong các tình huống phức tạp hơn. Học sâu có thể xử lý được các mối quan hệ phi tuyến và phức tạp trong dữ liệu, từ đó gia tăng độ chính xác và hiệu quả trong phát hiện gian lận. Ngoài ra, nghiên cứu có thể mở rộng sang các lĩnh vực khác như bảo hiểm, thương mại điện tử, nơi mà gian lận cũng là một vấn đề đáng lo ngại. Việc áp dụng học máy trong những lĩnh vực này có thể mang lại nhiều giá trị và cơ hội mới cho các tổ chức. Việc tiến hành các nghiên cứu thực nghiệm đa dạng hơn với các bộ dữ liệu lớn và phong phú sẽ giúp củng cố và mở rộng những phát hiện của nghiên cứu. Điều này không chỉ giúp nâng cao hiểu biết về ứng dụng của học máy mà còn góp phần vào việc xây dựng các hệ thống phát hiện gian lận hiệu quả hơn trong tương lai.
Tài liệu tham khảo:
1. T. N. Đ. Tiến (2023). Phát triển ngân hàng số ở Việt Nam. Nghiên cứu Tài chính kế toán.
2. The European Centre for Research Training and Development -UK (2023). Machine Learning Approaches for Enhancing Fraud Prevention in Financial Transactions. International Journal of Management Technology.
3. Đ. T. H, Đào Mỹ Hằng (2021). Ứng dụng dữ liệu lớn – thách thức đối với các ngân hàng thương mại Việt Nam. Khoa học và Đào tạo ngân hàng.
4. F. Alarfaj, I. Malik, H. Khan, N. Almusallam and M. R. v. M. Ahmed (2022). Credit Card Fraud Detection Using State-of-the-Art Machine Learning and Deep Learning Algorithms.
5. N. T. Hiền, P. T. Hương (2019). Ứng dụng công nghệ tài chính trong kinh doanh ngân hàng tại Việt Nam – xu hướng tất yếu của thời đại 4.0. Khoa học thương mại.
6. R. B. Sulaiman andV. S. &. P. Sant (2022). Review of Machine Learning Approach on Credit Card Fraud Detection, pp. 55 – 68.
7. T. K. Ngọc and N. K. Duy (2021). Bản chất của dịch vụ ngân hàng và các hình thái phát triển của nó trong bối cảnh ứng dụng công nghệ. Khoa học và Đào tạo ngân hàng.
8. P. T. K. Nhi, N. T. H. Nhung và N. T. T. Thảo (2022). Chuyển đổi số – ứng dụng trí tuệ nhân tạo và công nghệ điện toán đám mây vào hoạt động của các ngân hàng thương mại Việt Nam. Dịch vụ ngân hàng điện tử và ngân hàng số.
9. H. T. Thuý and L. T. X. Thu (2021). Phát hiện gian lận thẻ tín dụng bằng học máy. Kinh tế và Phát triển.
10. N. V. Thuỷ (2024). Nhận diện các công nghệ mới nổi ứng dụng trong các mô hình ngân hàng trên nền tảng số. Kinh tế – Luật và Ngân hàng.
11. V. T. N. Hà, L. N. P. Đ. Đài, T. P. Thịnh, P. V. Đồng và T. T. H. Anh (2023). Chuyển đổi số trong ngành ngân hàng. Khoa học Yersin – Chuyên đề quản lý kinh tế.



