
Predicting bankruptcy risk of listed firms in the stock market: a machine learning approach using logistic regression
ThS. Nguyễn Trung Đông
TS. Nguyễn Ngọc Tuyến
Trường Đại học Tài chính – Marketing
ThS. Vũ Ninh Thơ
Thuế Thành phố Hồ Chí Minh
(Quanlynhanuoc.vn) – Nghiên cứu dự báo rủi ro phá sản của các doanh nghiệp niêm yết trên thị trường chứng khoán Việt Nam giai đoạn 2010 – 2025 theo tiếp cận học máy dựa trên mô hình hồi quy logistic. Dữ liệu tài chính theo quý của 123 doanh nghiệp thuộc ngành nguyên vật liệu, trong đó biến phụ thuộc phản ánh tình trạng rủi ro phá sản, các biến giải thích đại diện cho thanh khoản, khả năng tích lũy nội lực, quy mô, cấu trúc tài chính và hiệu quả hoạt động. Do tồn tại tình trạng mất cân bằng dữ liệu, nghiên cứu áp dụng kỹ thuật tái lấy mẫu SMOTE trên tập huấn luyện nhằm cải thiện khả năng nhận diện nhóm doanh nghiệp có nguy cơ phá sản. Kết quả thực nghiệm cho thấy, mô hình hồi quy logistic đạt độ phù hợp cao và khả năng dự báo tốt. Trong đó, các chỉ tiêu phản ánh năng lực tài chính nội sinh và hiệu quả hoạt động có tác động mạnh nhất đến xác suất phá sản. Từ đó, nghiên cứu đề xuất một công cụ cảnh báo sớm hữu ích, góp phần hỗ trợ nhà đầu tư và cơ quan quản lý trong việc giám sát và phòng ngừa rủi ro trên thị trường chứng khoán Việt Nam.
Từ khóa: Phá sản doanh nghiệp; dự báo rủi ro; hồi quy logistic; dữ liệu mất cân bằng; SMOTE; thị trường chứng khoán Việt Nam.
Abstract: This study forecasts bankruptcy risk among firms listed on the Vietnamese stock market over the 2010-2025 period using a machine learning approach based on Logistic Regression. Quarterly financial data from 123 firms in the Materials sector are employed. The dependent variable captures bankruptcy risk status, while explanatory variables proxy for liquidity, internal capital accumulation capacity, firm size, financial structure, and operating performance. Given the class imbalance in the dataset, the Synthetic Minority Over-sampling Technique (SMOTE) is applied to the training set. The empirical results indicate that the Logistic model exhibits strong goodness-of-fit and robust predictive performance in identifying bankruptcy risk. Indicators reflecting endogenous financial capacity and operating efficiency exert the most pronounced effects. The findings provide a valuable early warning tool for investors and regulatory authorities.
Keywords: Corporate bankruptcy; risk prediction; logistic regression; imbalanced data; SMOTE; Vietnamese stock market.
1. Đặt vấn đề
Phá sản doanh nghiệp là một trong những rủi ro nghiêm trọng nhất trong hoạt động sản xuất – kinh doanh, phản ánh sự suy giảm toàn diện về năng lực tài chính và khả năng duy trì hoạt động của doanh nghiệp. Trên thị trường chứng khoán, các trường hợp doanh nghiệp rơi vào tình trạng phá sản hoặc có nguy cơ phá sản không chỉ gây thiệt hại cho doanh nghiệp mà còn ảnh hưởng trực tiếp đến quyền lợi của nhà đầu tư, tổ chức tín dụng và sự ổn định chung của thị trường. Trong giai đoạn 2010 – 2025, thị trường chứng khoán Việt Nam chứng kiến sự gia tăng đáng kể về số lượng doanh nghiệp niêm yết, đi kèm với đó là những biến động mạnh về môi trường kinh doanh và điều kiện tài chính. Bên cạnh các doanh nghiệp duy trì được tốc độ tăng trưởng ổn định, vẫn tồn tại một bộ phận doanh nghiệp rơi vào tình trạng khó khăn tài chính kéo dài, thua lỗ liên tục và có nguy cơ phá sản. Thực tiễn này đặt ra yêu cầu cấp thiết về việc xây dựng các công cụ dự báo rủi ro phá sản nhằm hỗ trợ công tác giám sát, quản trị rủi ro và ra quyết định của các chủ thể trên thị trường.
Trong nghiên cứu tài chính doanh nghiệp, dự báo phá sản thường được tiếp cận thông qua các mô hình định lượng dựa trên chỉ tiêu tài chính. Tuy nhiên, nhiều phương pháp truyền thống chủ yếu dựa trên các ngưỡng kế toán cố định hoặc giả định mối quan hệ tuyến tính đơn giản, do đó, chưa phản ánh đầy đủ bản chất xác suất và tính không chắc chắn của hiện tượng phá sản. Trong bối cảnh dữ liệu tài chính ngày càng phong phú, các phương pháp học máy được xem là một hướng tiếp cận phù hợp để nâng cao khả năng dự báo rủi ro tài chính. Trong số các phương pháp học máy, mô hình hồi quy logistic được sử dụng rộng rãi trong các bài toán phân loại nhị phân, đặc biệt là dự báo rủi ro phá sản doanh nghiệp. Mô hình này cho phép ước lượng trực tiếp xác suất xảy ra sự kiện phá sản dựa trên các đặc trưng tài chính của doanh nghiệp; đồng thời, không đòi hỏi giả định phân phối chuẩn của biến giải thích. Bên cạnh đó, hồi quy logistic vẫn duy trì được khả năng diễn giải rõ ràng thông qua hệ số và tỷ lệ odds, phù hợp với yêu cầu phân tích và ứng dụng trong lĩnh vực tài chính, kế toán. Xuất phát từ thực tiễn trên, nghiên cứu này tập trung xây dựng mô hình hồi quy logistic nhằm dự báo rủi ro phá sản của các doanh nghiệp niêm yết trên thị trường chứng khoán Việt Nam trong giai đoạn 2010 – 2025. Thông qua đó, nghiên cứu kỳ vọng cung cấp thêm bằng chứng thực nghiệm về khả năng ứng dụng mô hình học máy logistic trong công tác dự báo rủi ro phá sản doanh nghiệp tại Việt Nam.
2. Mô hình nghiên cứu
2.1. Dữ liệu nghiên cứu và phạm vi mẫu
Nghiên cứu sử dụng dữ liệu tài chính theo quý của các doanh nghiệp niêm yết trên thị trường chứng khoán Việt Nam trong giai đoạn 2010 – 2025. Mẫu nghiên cứu bao gồm 123 doanh nghiệp niêm yết trên Sở Giao dịch Chứng khoán TP. Hồ Chí Minh (HOSE) và Sở Giao dịch Chứng khoán Hà Nội (HNX). Sau quá trình thu thập, sàng lọc và xử lý dữ liệu, bộ dữ liệu cuối cùng gồm 5.338 quan sát theo cấu trúc dữ liệu bảng không cân bằng. Việc sử dụng dữ liệu theo quý cho phép nghiên cứu phản ánh kịp thời hơn các biến động trong tình hình tài chính của doanh nghiệp, đặc biệt trong bối cảnh rủi ro phá sản thường phát sinh và diễn biến theo thời gian. Đồng thời, dữ liệu bảng không cân bằng phản ánh đặc điểm thực tế của thị trường chứng khoán Việt Nam, nơi thời gian niêm yết và khả năng công bố thông tin của các doanh nghiệp không đồng nhất.
2.2. Xây dựng biến phụ thuộc
Biến phụ thuộc trong nghiên cứu là biến nhị phân Bankrupt, phản ánh trạng thái rủi ro phá sản của doanh nghiệp tại từng thời điểm quan sát. Biến này được mã hóa như sau:
– Bankrupt = 1: doanh nghiệp được xác định là có nguy cơ phá sản.
– Bankrupt = 0: doanh nghiệp được xác định là không có nguy cơ phá sản.
Việc xây dựng biến phụ thuộc dưới dạng nhị phân phù hợp với mục tiêu nghiên cứu là dự báo khả năng xảy ra rủi ro phá sản; đồng thời, phù hợp với bản chất của mô hình hồi quy logistic – một mô hình phân loại xác suất dành cho biến phụ thuộc dạng rời rạc hai trạng thái.
2.3. Lựa chọn biến độc lập
Dựa trên dữ liệu tài chính của doanh nghiệp, nghiên cứu lựa chọn năm biến độc lập đại diện cho các khía cạnh cốt lõi của tình hình tài chính doanh nghiệp, bao gồm: thanh khoản, khả năng sinh lời, quy mô, cấu trúc vốn theo đánh giá thị trường và hiệu quả hoạt động. Các biến độc lập được sử dụng trong mô hình bao gồm:
X1 – vốn lưu động/tổng tài sản: phản ánh khả năng thanh khoản và mức độ linh hoạt tài chính ngắn hạn của doanh nghiệp. Giá trị X1 cao cho thấy, doanh nghiệp có khả năng đáp ứng tốt hơn các nghĩa vụ tài chính ngắn hạn, từ đó, làm giảm rủi ro phá sản.
X2 – lợi nhuận giữ lại/tổng tài sản: phản ánh năng lực tích lũy nội lực tài chính của doanh nghiệp trong dài hạn. Lợi nhuận giữ lại đóng vai trò như một “lớp đệm” tài chính giúp doanh nghiệp chống chịu các cú sốc bất lợi từ môi trường kinh doanh, qua đó, làm giảm xác suất phá sản.
X3 – Log (tổng tài sản): đại diện cho quy mô doanh nghiệp. Quy mô lớn thường gắn với khả năng tiếp cận nguồn vốn tốt hơn, mức độ đa dạng hóa hoạt động cao hơn và khả năng chống chịu rủi ro tốt hơn so với các doanh nghiệp quy mô nhỏ.
X4 – giá trị thị trường vốn chủ sở hữu/tổng nợ: biến X4 phản ánh mối quan hệ giữa giá trị thị trường của doanh nghiệp và mức độ sử dụng nợ, qua đó, thể hiện đánh giá của thị trường đối với sức khỏe tài chính và cấu trúc vốn của doanh nghiệp.
X5 – doanh thu/tổng tài sản: đo lường hiệu quả sử dụng tài sản trong việc tạo ra doanh thu. Doanh nghiệp có hiệu quả hoạt động cao thường có dòng tiền ổn định hơn, từ đó, giảm nguy cơ rơi vào tình trạng khó khăn tài chính và phá sản.
Việc lựa chọn các biến trên nhằm bảo đảm mô hình phản ánh đầy đủ các khía cạnh quan trọng nhất của tình hình tài chính doanh nghiệp; đồng thời, tránh trùng lặp thông tin và phù hợp với dữ liệu thực tế thu thập được.
2.4. Đặc tả mô hình hồi quy logistic
Để dự báo rủi ro phá sản của doanh nghiệp, nghiên cứu sử dụng mô hình hồi quy logistic với dạng tổng quát như sau:
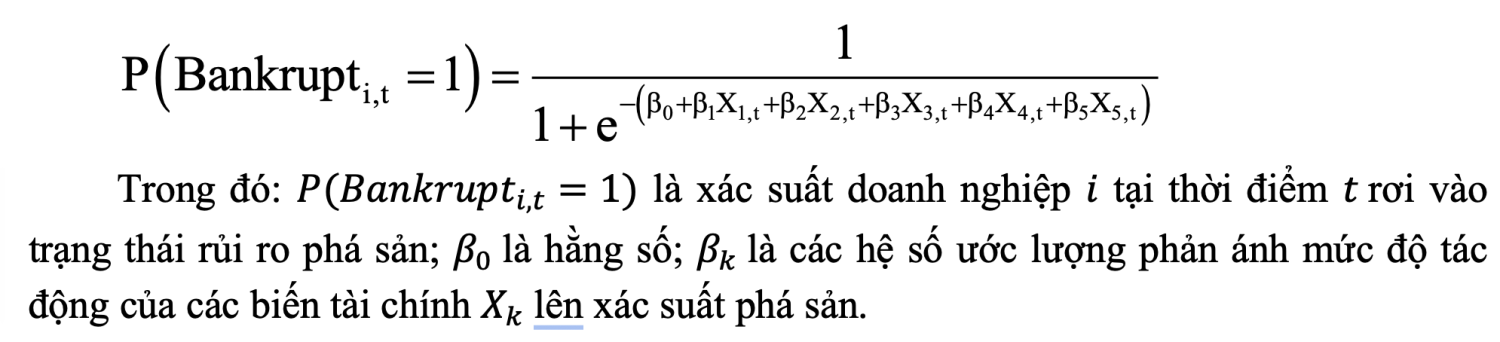
Mô hình Logistic sử dụng hàm liên kết logit để chuyển đổi xác suất xảy ra sự kiện phá sản sang dạng log-odds (log-odds: logarit tự nhiên của odds, trong đó odds là tỷ số giữa xác suất xảy ra sự kiện và xác suất không xảy ra sự kiện) tuyến tính theo các biến giải thích. Cách tiếp cận này cho phép xác suất dự báo luôn nằm trong khoảng [0;1] và không yêu cầu giả định phân phối chuẩn của các biến độc lập. Cụ thể, hệ số dương cho thấy, biến độc lập làm tăng xác suất phá sản, trong khi hệ số âm cho thấy, biến độc lập làm giảm xác suất phá sản. Ngoài ra, các hệ số có thể được chuyển đổi sang dạng tỷ lệ odds để thuận tiện cho việc diễn giải trong bối cảnh quản trị rủi ro.
2.5. Xử lý dữ liệu mất cân bằng và chia tập dữ liệu
Một đặc điểm quan trọng của bộ dữ liệu nghiên cứu là sự mất cân bằng giữa hai nhóm doanh nghiệp. Trong tổng số 5.338 quan sát, số quan sát thuộc nhóm không phá sản chiếm tỷ trọng lớn hơn đáng kể so với nhóm có nguy cơ phá sản. Tình trạng mất cân bằng này có thể dẫn đến sai lệch trong quá trình huấn luyện mô hình, khi mô hình có xu hướng ưu tiên dự báo đúng nhóm chiếm đa số.
Để khắc phục vấn đề này, dữ liệu được chia thành hai tập: tập huấn luyện chiếm 70% tổng số quan sát và tập kiểm định chiếm 30% tổng số quan sát.
(1) Tập huấn luyện, nghiên cứu áp dụng kỹ thuật SMOTE (Synthetic Minority Over-sampling Technique) nhằm cân bằng số lượng quan sát giữa hai nhóm phá sản và không phá sản. SMOTE tạo ra các quan sát tổng hợp cho nhóm thiểu số dựa trên phương pháp nội suy, giúp mô hình học tốt hơn các đặc điểm của nhóm doanh nghiệp có nguy cơ phá sản. Việc áp dụng SMOTE chỉ thực hiện trên tập huấn luyện nhằm tránh hiện tượng rò rỉ thông tin và bảo đảm tính khách quan của kết quả đánh giá trên tập kiểm định.
(2) Tập kiểm định, nghiên cứu áp dụng kỹ thuật tái lấy mẫu SMOTE (Synthetic Minority Over-sampling Technique) nhằm xử lý tình trạng mất cân bằng dữ liệu, qua đó, cân bằng số lượng quan sát giữa hai nhóm doanh nghiệp phá sản và không phá sản. Cụ thể, SMOTE tạo ra các quan sát tổng hợp cho nhóm thiểu số thông qua nội suy giữa các điểm dữ liệu lân cận trong không gian đặc trưng, giúp mô hình học hiệu quả hơn các đặc điểm của nhóm doanh nghiệp có nguy cơ phá sản. Việc áp dụng SMOTE được giới hạn trong tập huấn luyện nhằm tránh hiện tượng rò rỉ thông tin và bảo đảm tính khách quan khi đánh giá hiệu quả dự báo trên tập kiểm định.
2.6. Tiêu chí đánh giá mô hình
Hiệu quả của mô hình hồi quy logistic được đánh giá thông qua các chỉ tiêu phân loại phổ biến trong bài toán dự báo nhị phân, bao gồm: độ chính xác, độ bao phủ, độ chính xác dự báo dương, chỉ số F1-score và diện tích dưới đường cong ROC (AUC). Bên cạnh đó, ma trận nhầm lẫn được sử dụng để phân tích chi tiết số trường hợp dự báo đúng và sai của mô hình. Trong bối cảnh dữ liệu mất cân bằng, nghiên cứu đặc biệt chú trọng đến các chỉ tiêu như Recall, F1-score và AUC, bởi các chỉ tiêu này phản ánh tốt hơn khả năng phát hiện đúng các trường hợp doanh nghiệp có nguy cơ phá sản, thay vì chỉ dựa vào độ chính xác tổng thể.
3. Kết quả nghiên cứu và thảo luận
3.1. Mô tả dữ liệu
Nghiên cứu sử dụng dữ liệu tài chính theo quý của các doanh nghiệp thuộc ngành Nguyên vật liệu đang niêm yết hoặc đã từng niêm yết trên hai Sở Giao dịch Chứng khoán Việt Nam (HOSE và HNX). Dữ liệu được thu thập trong giai đoạn từ quý III/2010 – quý I/2025, cho phép quan sát đầy đủ diễn biến hoạt động cũng như rủi ro phá sản của doanh nghiệp trong dài hạn. Mẫu nghiên cứu bao gồm 123 doanh nghiệp, được xác định sau quá trình sàng lọc dữ liệu theo các tiêu chí về tính đầy đủ và nhất quán của thông tin tài chính theo quý. Mẫu bao gồm cả các doanh nghiệp đang hoạt động và các doanh nghiệp đã bị hủy niêm yết do thua lỗ kéo dài, vi phạm nghĩa vụ công bố thông tin hoặc không đáp ứng các yêu cầu về vốn.
Do sự khác biệt về thời điểm niêm yết và rút khỏi thị trường giữa các doanh nghiệp, bộ dữ liệu có cấu trúc bảng không cân bằng. Sau quá trình xử lý và làm sạch, nghiên cứu thu được 5.338 quan sát hợp lệ, mỗi quan sát tương ứng với một doanh nghiệp tại một quý tài chính. Biến phụ thuộc trong mô hình là Bankrupt, được xây dựng dưới dạng biến nhị phân, nhận giá trị 1 nếu doanh nghiệp được xác định có nguy cơ phá sản và 0 nếu doanh nghiệp hoạt động ổn định. Để dự báo rủi ro phá sản, nghiên cứu sử dụng năm biến độc lập là các chỉ tiêu tài chính phổ biến, bao gồm: vốn lưu động/tổng tài sản, đại diện cho khả năng thanh khoản; lợi nhuận giữ lại/tổng tài sản phản ánh khả năng tích lũy nội lực; logarit tổng tài sản, đại diện cho quy mô doanh nghiệp; giá trị thị trường vốn chủ sở hữu/tổng nợ, đo lường mức độ rủi ro tài chính; và doanh thu/tổng tài sản phản ánh hiệu quả sử dụng tài sản. Để xây dựng và đánh giá mô hình hồi quy logistic trong khuôn khổ tiếp cận học máy, dữ liệu được chia ngẫu nhiên thành tập huấn luyện (70%) và tập kiểm tra (30%). Cách phân chia này giúp bảo đảm tính khách quan trong quá trình ước lượng; đồng thời, cho phép đánh giá khả năng tổng quát hóa của mô hình trên dữ liệu chưa quan sát, phù hợp với thông lệ trong các nghiên cứu thực nghiệm gần đây.
3.2. Thống kê mô tả
– Thống kê mô tả cho dữ liệu gốc
Bảng 1. Thống kê mô tả tập huấn luyện
| Các công ty ổn định | |||||
| Chỉ tiêu | X1 | X2 | X3 | X4 | X5 |
| Số lượng | 3298 | 3298 | 3298 | 3298 | 3298 |
| Trung bình | 0,213 | 0,0166 | 20,4 | 3,65 | 0,291 |
| Độ lệch chuẩn | 0,228 | 0,0234 | 1,50 | 15,1 | 0,217 |
| Nhỏ nhất | -0,613 | -0,197 | 17 | 0 | 0 |
| Lớn nhất | 0,997 | 0,244 | 26.2 | 362 | 2,29 |
| Các công ty phá sản | |||||
| Số lượng | 439 | 439 | 439 | 439 | 439 |
| Trung bình | 0,0403 | -0,0218 | 19,6 | 1,74 | 0,132 |
| Độ lệch chuẩn | 0,310 | 0.0704 | 1,38 | 9,23 | 0,125 |
| Nhỏ nhất | -1,520 | -1,310 | 17,3 | 0 | -0,002 |
| Lớn nhất | 0,980 | 0,020 | 23,2 | 182 | 0,696 |
Bảng 1 trình bày thống kê mô tả các biến nghiên cứu trong tập dữ liệu huấn luyện, bao gồm 3.298 quan sát thuộc nhóm doanh nghiệp ổn định và 439 quan sát thuộc nhóm doanh nghiệp có nguy cơ phá sản. Kết quả cho thấy, sự khác biệt rõ rệt về đặc điểm tài chính giữa hai nhóm doanh nghiệp. Cụ thể, các doanh nghiệp ổn định có khả năng thanh khoản (X1) cao hơn đáng kể so với nhóm phá sản, với giá trị trung bình lần lượt là 0,213 và 0,0403. Tương tự, khả năng tích lũy nội lực (X2) của nhóm ổn định có giá trị trung bình dương, trong khi nhóm phá sản có giá trị trung bình âm, phản ánh tình trạng suy giảm tài chính kéo dài của các doanh nghiệp có nguy cơ phá sản. Về quy mô doanh nghiệp (X3), nhóm ổn định có quy mô trung bình lớn hơn so với nhóm phá sản (20,4 so với 19,6).
Ngoài ra, tỷ lệ giá trị thị trường vốn chủ sở hữu trên tổng nợ (X4) và hiệu quả sử dụng tài sản (X5) của nhóm doanh nghiệp ổn định đều cao hơn đáng kể so với nhóm phá sản, cho thấy cấu trúc tài chính lành mạnh và hiệu quả hoạt động tốt hơn. Nhìn chung, các chỉ tiêu thống kê mô tả trong tập huấn luyện cho thấy, các doanh nghiệp có nguy cơ phá sản có đặc điểm tài chính kém hơn một cách nhất quán, tạo cơ sở thực nghiệm cho việc xây dựng mô hình dự báo rủi ro phá sản.
Bảng 2. Thống kê mô tả tập kiểm tra
| Các công ty ổn định | |||||
| Chỉ tiêu | X1 | X2 | X3 | X4 | X5 |
| Số lượng | 1401 | 1401 | 1401 | 1401 | 1401 |
| Trung bình | 0,213 | 0,0182 | 20,5 | 3,36 | 0,31 |
| Độ lệch chuẩn | 0,223 | 0,0253 | 1,55 | 12,9 | 0,22 |
| Nhỏ nhất | -0,515 | -0,0932 | 17,1 | 0,00 | 0,00 |
| Lớn nhất | 0,936 | 0,319 | 26,1 | 202 | 1,86 |
| Các công ty phá sản | |||||
| Số lượng | 200 | 200 | 200 | 200 | 200 |
| Trung bình | 0,0535 | -0,019 | 19,5 | 2,24 | 0,132 |
| Độ lệch chuẩn | 0,322 | 0,0334 | 1,28 | 6,07 | 0,130 |
| Nhỏ nhất | -0,695 | -0,343 | 17,4 | 0,00 | -0,002 |
| Lớn nhất | 0,937 | 0,0074 | 23,5 | 37,7 | 0,579 |
Bảng 2 báo cáo thống kê mô tả các biến trong tập kiểm tra với 1.401 quan sát thuộc nhóm doanh nghiệp ổn định và 200 quan sát thuộc nhóm có nguy cơ phá sản, tiếp tục phản ánh đặc điểm mất cân bằng của dữ liệu. Kết quả cho thấy, nhóm doanh nghiệp ổn định có nền tảng tài chính vững hơn: giá trị trung bình của thanh khoản (X1), khả năng tích lũy nội lực (X2), quy mô (X3), tỷ lệ giá trị thị trường vốn chủ sở hữu trên tổng nợ (X4) và hiệu quả sử dụng tài sản (X5) đều cao hơn so với nhóm phá sản. Ngược lại, nhóm phá sản có mức trung bình thấp hơn và độ phân tán lớn hơn ở một số chỉ tiêu, hàm ý mức độ rủi ro tài chính cao hơn. Các đặc điểm này tương đồng với tập huấn luyện, bảo đảm tính nhất quán của cấu trúc dữ liệu và tạo cơ sở tin cậy cho việc đánh giá hiệu quả dự báo của mô hình logistic trên mẫu ngoài.
– Thống kê mô tả cho dữ liệu bằng phương pháp SMOTE
Bảng 3. Thống kê mô tả tập huấn luyện
| Các công ty ổn định | |||||
| Chỉ tiêu | X1 | X2 | X3 | X4 | X5 |
| Số lượng | 3298 | 3298 | 3298 | 3298 | 3298 |
| Trung bình | 0,213 | 0,0166 | 20,4 | 3,65 | 0,291 |
| Độ lệch chuẩn | 0,228 | 0,0234 | 1,50 | 15,1 | 0,217 |
| Nhỏ nhất | -0,613 | -0,197 | 17,0 | 0,00 | 0,00 |
| Lớn nhất | 0,997 | 0.244 | 26,2 | 362 | 2,29 |
| Các công ty phá sản | |||||
| Số lượng | 3298 | 3298 | 3298 | 3298 | 3298 |
| Trung bình | 0,035 | -0,0192 | 19,6 | 1,48 | 0,0129 |
| Độ lệch chuẩn | 0,289 | 0,0418 | 1,37 | 5,67 | 0,113 |
| Nhỏ nhất | -1,52 | -1,31 | 17,3 | 0,00 | -0,0017 |
| Lớn nhất | 0,98 | 0,020 | 23,2 | 182 | 0,696 |
Bảng 3 trình bày thống kê mô tả tập huấn luyện sau khi áp dụng SMOTE là một kỹ thuật tái lấy mẫu được đề xuất bởi Chawla et al. (2002) nhằm xử lý dữ liệu mất cân bằng trong các bài toán phân loại nhị phân, với số quan sát được cân bằng giữa hai nhóm (3.298 doanh nghiệp ổn định và 3.298 doanh nghiệp có nguy cơ phá sản). Việc tái lấy mẫu giúp khắc phục tình trạng mất cân bằng trong dữ liệu gốc, hạn chế sai lệch trong quá trình huấn luyện mô hình. Các đặc trưng của nhóm doanh nghiệp ổn định hầu như không thay đổi, cho thấy SMOTE chỉ tác động đến nhóm thiểu số. Đối với nhóm phá sản, các chỉ tiêu thanh khoản (X1), khả năng tích lũy nội lực (X2), quy mô (X3), tỷ lệ giá trị thị trường vốn chủ sở hữu trên tổng nợ (X4) và hiệu quả sử dụng tài sản (X5) vẫn thấp hơn so với nhóm ổn định; đồng thời, độ phân tán tương đối lớn phản ánh mức độ bất ổn tài chính. Nhìn chung, sự khác biệt giữa hai nhóm được bảo toàn sau khi cân bằng mẫu, tạo điều kiện thuận lợi cho mô hình Logistic học và nhận diện rủi ro phá sản.
3.3. Ma trận tương quan
Bảng 4. Ma trận tương quan giữa các biến
| Bankrupt | -0,22 | -0,37 | -0,18 | -0,04 | -0,25 | 1,00 |
| X1 | 0,10 | 0,20 | -0,02 | -0,10 | 1,00 | -0,25 |
| X2 | 0,16 | 0,09 | -0,09 | 1,00 | -0,10 | -0,04 |
| X3 | -0,19 | 0,05 | 1,00 | -0,09 | -0,02 | -0,18 |
| X4 | 0,25 | 1,00 | 0,05 | 0,09 | 0,20 | -0,37 |
| X5 | 1,00 | 0,25 | -0,19 | 0,16 | 0,10 | -0,22 |
| X1 | X2 | X3 | X4 | X5 | Bankrupt |
Bảng 4 trình bày ma trận tương quan giữa biến phụ thuộc Bankrupt và các biến giải thích trong mô hình. Kết quả cho thấy, Bankrupt có mối tương quan âm với tất cả các biến tài chính, trong đó mức tương quan lớn nhất lần lượt thuộc về X1 (-0,37), X2 (-0,25) và X3 (-0,22), phản ánh xu hướng rủi ro phá sản giảm khi tình hình tài chính doanh nghiệp được cải thiện. Giữa các biến độc lập, hệ số tương quan nhìn chung ở mức thấp, không có cặp biến nào có tương quan tuyệt đối lớn cho thấy, không tồn tại hiện tượng tương quan cao giữa các biến giải thích. Kết quả này hàm ý nguy cơ đa cộng tuyến trong mô hình hồi quy logistic là không đáng kể, tạo điều kiện thuận lợi cho việc ước lượng và diễn giải kết quả mô hình.
3.4. Kiểm định đa cộng tuyến
Bảng 5. Kết quả kiểm định đa cộng tuyến
| Biến | X1 | X2 | X3 | X4 | X5 |
| VIF | 1,139 | 1,120 | 1,055 | 1,050 | 1,062 |
Bảng 5 trình bày kết quả kiểm định đa cộng tuyến giữa các biến giải thích trong mô hình thông qua chỉ số VIF (Variance Inflation Factor). Kết quả cho thấy, giá trị VIF của các biến X1 – X2 dao động trong khoảng từ 1,139 – 1,120, đều thấp hơn đáng kể so với ngưỡng cảnh báo thường được sử dụng. Điều này cho thấy không tồn tại hiện tượng đa cộng tuyến nghiêm trọng giữa các biến độc lập trong mô hình. Do đó, các ước lượng hồi quy logistic có thể được xem là ổn định và đáng tin cậy; đồng thời, việc diễn giải tác động riêng lẻ của từng biến tài chính đến rủi ro phá sản là phù hợp.
3.5. Kết quả thực nghiệm
– Phân tích cấu trúc dữ liệu trước và sau khi lấy mẫu lại bằng SMOTE
Bảng 6. Chia dữ liệu huấn luyện và thử nghiệm
| Các công ty ổn định | Các công ty phá sản | Tổng cộng | |
| Tập huấn luyện (70%) | 3298 | 439 | 3737 |
| Tập thử nghiệm (30%) | 1401 | 200 | 1601 |
| Tổng cộng | 4699 | 639 | 5338 |
Bảng 6 trình bày cấu trúc dữ liệu nghiên cứu sau khi chia mẫu thành tập huấn luyện (70%) và tập thử nghiệm (30%). Trong tổng số 5.338 quan sát, tập huấn luyện bao gồm 3.737 quan sát, trong đó có 3298 doanh nghiệp ổn định và 439 doanh nghiệp có nguy cơ phá sản; tập thử nghiệm gồm 1.601 quan sát, với 1.401 doanh nghiệp ổn định và 200 doanh nghiệp có nguy cơ phá sản. Cấu trúc này cho thấy sự mất cân bằng rõ rệt giữa hai nhóm doanh nghiệp trong cả hai tập dữ liệu, đặc biệt là tỷ trọng doanh nghiệp phá sản chiếm tỷ lệ nhỏ hơn đáng kể. Do đó, việc áp dụng phương pháp SMOTE trên tập huấn luyện là cần thiết nhằm cân bằng mẫu, giúp mô hình học máy cải thiện khả năng nhận diện các doanh nghiệp có nguy cơ phá sản mà không làm ảnh hưởng đến tính khách quan của tập thử nghiệm.
Bảng 7. Số quan sát trước và sau khi lấy lại mẫu
| Phân loại công ty | Dữ liệu gốc | Lấy mẫu lại | |
| Phương pháp SMOTE | Các công ty ổn định | 4699 | 3298 |
| Các công ty phá sản | 639 | 3298 | |
| Tổng cộng | 5338 | 6596 |
Bảng 7 trình bày sự thay đổi về số lượng quan sát của hai nhóm doanh nghiệp trước và sau khi áp dụng phương pháp SMOTE trên tập dữ liệu huấn luyện. Trong dữ liệu gốc, số quan sát thuộc nhóm doanh nghiệp ổn định là 4.699, trong khi nhóm doanh nghiệp có nguy cơ phá sản chỉ có 639 quan sát, phản ánh rõ tình trạng mất cân bằng lớp trong mẫu nghiên cứu. Sau khi lấy mẫu lại bằng SMOTE, số quan sát của hai nhóm được cân bằng, cùng đạt 3298 quan sát cho mỗi nhóm, làm tăng tổng số quan sát lên 6596. Việc cân bằng dữ liệu thông qua SMOTE giúp cải thiện khả năng học của mô hình hồi quy logistic đối với nhóm doanh nghiệp có nguy cơ phá sản, đồng thời hạn chế sai lệch trong quá trình ước lượng do sự chênh lệch về quy mô mẫu giữa hai nhóm.
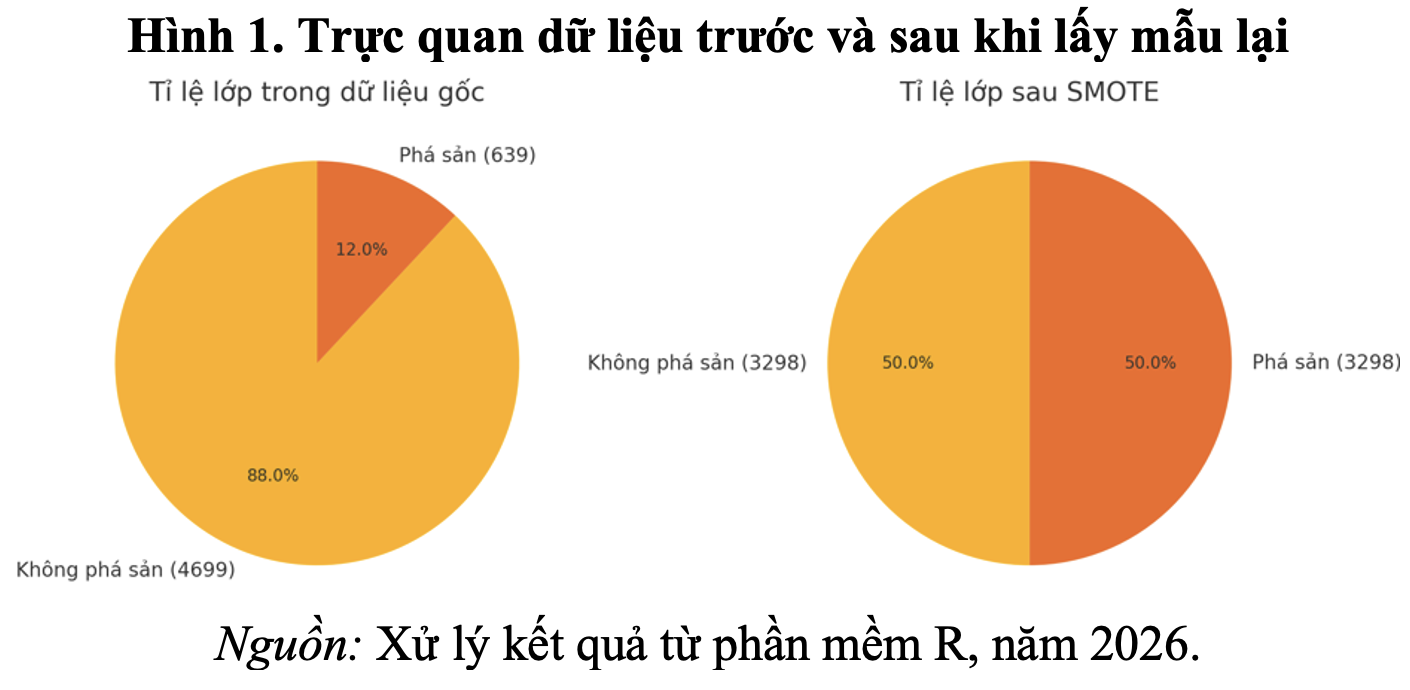
Hình 1 minh họa sự phân bố tỷ lệ các lớp trong dữ liệu trước và sau khi áp dụng phương pháp SMOTE. Trong dữ liệu gốc, nhóm doanh nghiệp không phá sản chiếm tỷ trọng lớn (88%), trong khi nhóm doanh nghiệp phá sản chỉ chiếm 12%, cho thấy, tình trạng mất cân bằng nghiêm trọng. Sau khi lấy mẫu lại bằng SMOTE, tỷ lệ hai nhóm được cân bằng ở mức 50 – 50%. Việc cân bằng này giúp cải thiện khả năng học và nhận diện lớp phá sản của mô hình dự báo.
– Mô hình Logistic
Bảng 8. Kết quả hồi quy Logistic
| R2 = 0,755 | |||||
| Bankrupt | Estimate | Std. Error | z value | Pr(>|z|) | |
| Intercept | 5,24836 | 0,67715 | 7,751 | 9,15e-15 *** | |
| X1 | -0,56480 | 0,17154 | -3,292 | 0,000993 *** | |
| X2 | -200,0214 | 6,29455 | -31,777 | <2e-16 *** | |
| X3 | -0,21371 | 0,03334 | -6,410 | 1,46e-10 *** | |
| X4 | -0,01487 | 0,00525 | -2,833 | 0,00461 *** | |
| X5 | -6,22498 | 0,35811 | -17,383 | <2e-16 *** | |
| Signif. codes: | 0 ‘***’ | 0,001 ‘**’ | 0,01 ‘*’ | 0,05 ‘.’ 0,1 ‘ ’ 1 | |
Bảng 8 trình bày kết quả hồi quy logistic cho mô hình dự báo rủi ro phá sản của doanh nghiệp niêm yết. Kết quả cho thấy, mô hình có mức độ phù hợp cao với dữ liệu nghiên cứu, thể hiện qua hệ số giải thích đạt R² = 0,775, cho thấy các biến tài chính được đưa vào mô hình giải thích tốt sự biến thiên của xác suất phá sản.
Xét về ý nghĩa thống kê, tất cả các biến độc lập từ X1 đến X5 đều có ý nghĩa ở mức 1% với giá trị thống kê z lớn về độ tuyệt đối và giá trị p rất nhỏ. Các hệ số ước lượng của các biến đều mang dấu âm, phản ánh mối quan hệ nghịch chiều giữa tình hình tài chính doanh nghiệp và xác suất phá sản. Điều này cho thấy, khi các chỉ tiêu tài chính được cải thiện, khả năng doanh nghiệp rơi vào tình trạng phá sản có xu hướng giảm.
Cụ thể, biến X1 (vốn lưu động/tổng tài sản) có hệ số âm và có ý nghĩa thống kê cao, cho thấy khả năng thanh khoản đóng vai trò quan trọng trong việc giảm thiểu rủi ro phá sản. Biến X3 (logarit tổng tài sản) phản ánh tác động của quy mô doanh nghiệp, với hệ số âm cho thấy các doanh nghiệp có quy mô lớn hơn thường có khả năng chống chịu rủi ro tốt hơn. Biến X4 (giá trị thị trường vốn chủ sở hữu/tổng nợ) cũng có tác động âm, phản ánh vai trò của cấu trúc tài chính và đánh giá thị trường trong việc dự báo rủi ro phá sản.
Đáng chú ý, hai biến X2 (lợi nhuận giữ lại/tổng tài sản) và X5 (doanh thu/tổng tài sản) có giá trị hệ số ước lượng lớn về độ tuyệt đối và mức ý nghĩa thống kê rất cao, đây là những yếu tố có tác động mạnh nhất đến xác suất phá sản. Kết quả này nhấn mạnh vai trò trung tâm của năng lực tài chính nội sinh và hiệu quả hoạt động trong việc dự báo rủi ro phá sản của doanh nghiệp niêm yết.
Nhìn chung, kết quả hồi quy logistic khẳng định mô hình được xây dựng là phù hợp, ổn định và có khả năng diễn giải rõ ràng, qua đó, tạo nền tảng vững chắc cho việc sử dụng mô hình trong công tác dự báo và cảnh báo sớm rủi ro phá sản doanh nghiệp.
– Hiệu suất của mô hình hồi quy logistic
Bảng 9. Kết quả hệ số hồi quy và Odds_Ratio
| Variable | Coefficient | Odds_Ratio |
| X1 | -0,564800 | 5,684743e-01 |
| X2 | -200,0214 | 1,354596e-87 |
| X3 | -0,213710 | 8,075806e-01 |
| X4 | -0,014870 | 9,852365e-01 |
| X5 | -6,224980 | 1,979365e-03 |
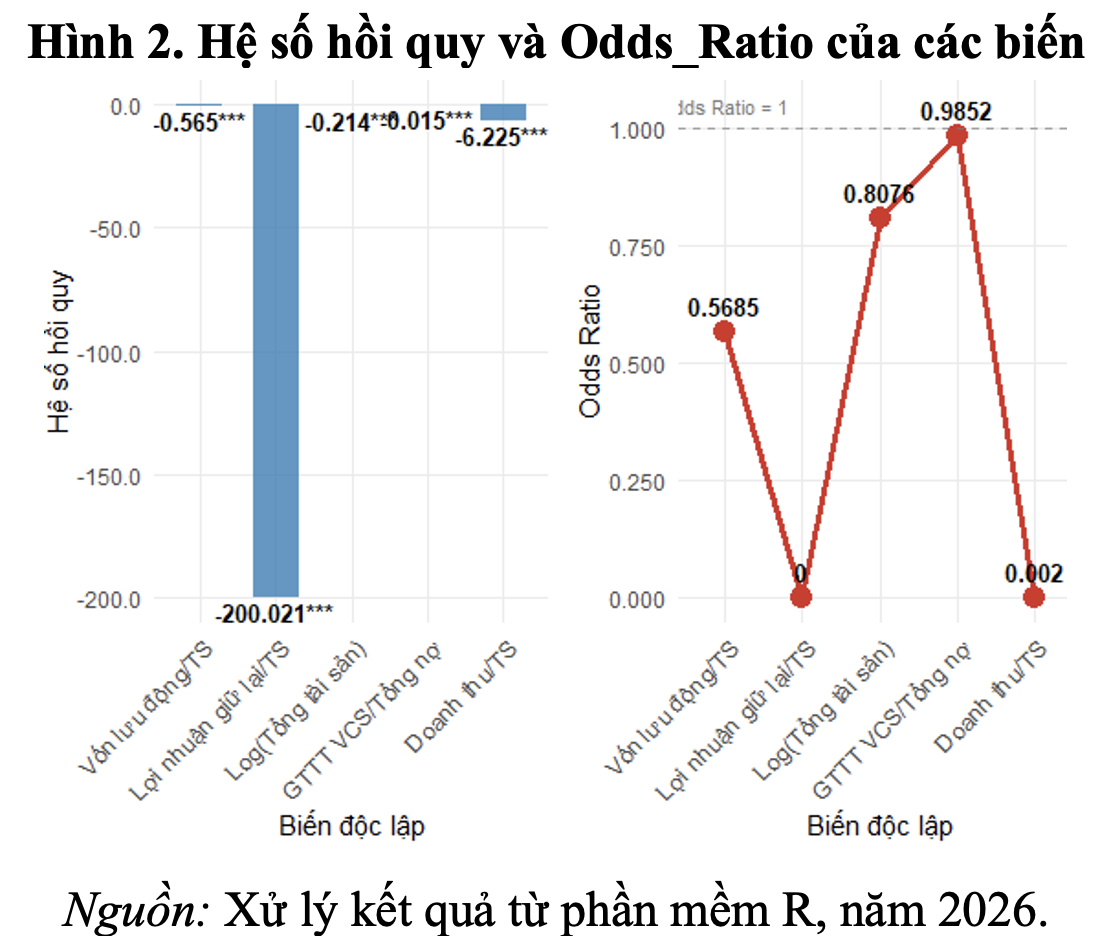
Bảng 9 và Hình 2 trình bày hệ số hồi quy và Odds Ratio (tỷ số phá sản so với không phá sản) của các biến trong mô hình logistic, qua đó, phản ánh mức độ và chiều tác động của từng yếu tố tài chính đến xác suất phá sản của doanh nghiệp. Kết quả cho thấy, tất cả các biến độc lập đều có hệ số hồi quy âm và Odds Ratio nhỏ hơn 1, khẳng định sự cải thiện của các chỉ tiêu tài chính đều góp phần làm giảm khả năng doanh nghiệp rơi vào trạng thái phá sản.
Cụ thể, biến X1 (vốn lưu động/tổng tài sản) có Odds Ratio xấp xỉ 0,57, cho thấy khi khả năng thanh khoản của doanh nghiệp tăng lên, xác suất phá sản giảm đáng kể. Biến X3 (logarit tổng tài sản) cũng có Odds Ratio nhỏ hơn 1 (khoảng 0,81), phản ánh vai trò của quy mô doanh nghiệp trong việc nâng cao khả năng chống chịu rủi ro tài chính. Đối với X4 (giá trị thị trường vốn chủ sở hữu/tổng nợ), Odds Ratio gần bằng 1 (0,99), cho thấy biến này có tác động làm giảm rủi ro phá sản nhưng với cường độ tương đối thấp so với các biến còn lại. Đáng chú ý, hai biến X2 (lợi nhuận giữ lại/tổng tài sản) và X5 (doanh thu/tổng tài sản) có Odds Ratio rất nhỏ, lần lượt ở mức 1,35×10^-87 và 0,002, phản ánh mức độ ảnh hưởng mạnh nhất đến xác suất phá sản. Kết quả này cho thấy các doanh nghiệp có năng lực tích lũy nội lực tài chính tốt và hiệu quả hoạt động cao sẽ giảm đáng kể nguy cơ phá sản, qua đó, nhấn mạnh vai trò trung tâm của nguồn lực tài chính nội sinh trong dự báo rủi ro phá sản. Nhìn chung, việc kết hợp phân tích hệ số hồi quy và Odds Ratio cho thấy mô hình logistic không chỉ có khả năng dự báo tốt mà còn cho phép lượng hóa rõ ràng mức độ tác động của từng yếu tố tài chính. Điều này giúp mô hình trở thành một công cụ hữu ích để đánh giá và cảnh báo sớm rủi ro phá sản của các doanh nghiệp niêm yết.
4. Kết luận và khuyến nghị
4.1. Kết luận
Nghiên cứu đã xây dựng và đánh giá mô hình hồi quy logistic nhằm dự báo rủi ro phá sản của các doanh nghiệp niêm yết trên thị trường chứng khoán Việt Nam trong giai đoạn 2010 – 2025. Kết quả thực nghiệm cho thấy, mô hình logistic có mức độ phù hợp cao với dữ liệu nghiên cứu, thể hiện qua hệ số giải thích lớn và các hệ số ước lượng có ý nghĩa thống kê. Các biến tài chính được lựa chọn trong mô hình đều có tác động nghịch chiều đến xác suất phá sản, cho thấy, khi tình hình tài chính doanh nghiệp được cải thiện thì rủi ro phá sản giảm. Đặc biệt, các chỉ tiêu phản ánh năng lực tài chính nội sinh và hiệu quả hoạt động, bao gồm: lợi nhuận giữ lại trên tổng tài sản và doanh thu trên tổng tài sản, đóng vai trò nổi bật trong việc dự báo rủi ro phá sản. Điều này cho thấy, rủi ro phá sản của doanh nghiệp niêm yết chủ yếu gắn liền với sự suy giảm kéo dài trong khả năng tạo lợi nhuận và dòng tiền hơn là các biến động ngắn hạn. Việc xử lý dữ liệu mất cân bằng bằng phương pháp SMOTE đã giúp cải thiện cấu trúc dữ liệu huấn luyện, qua đó, nâng cao khả năng nhận diện các doanh nghiệp có nguy cơ phá sản của mô hình. Kết quả đánh giá hiệu suất cho thấy, mô hình đạt khả năng phân biệt tốt giữa hai nhóm doanh nghiệp, đặc biệt là khả năng phát hiện các trường hợp có rủi ro phá sản, phù hợp với mục tiêu cảnh báo sớm trong quản trị rủi ro tài chính. Nhìn chung, nghiên cứu cung cấp bằng chứng thực nghiệm cho thấy, mô hình hồi quy logistic, khi được xây dựng trên cơ sở dữ liệu phù hợp và xử lý tốt các vấn đề kỹ thuật, có thể được sử dụng hiệu quả trong dự báo rủi ro phá sản của doanh nghiệp niêm yết tại Việt Nam.
4.2. Khuyến nghị
Thứ nhất, đối với doanh nghiệp niêm yết, cần chú trọng nâng cao năng lực tài chính nội sinh thông qua việc cải thiện hiệu quả hoạt động, duy trì lợi nhuận giữ lại và quản trị vốn lưu động hợp lý. Đây là những yếu tố có vai trò quan trọng trong việc giảm thiểu rủi ro phá sản theo kết quả mô hình.
Thứ hai, đối với nhà đầu tư và các tổ chức tài chính, mô hình hồi quy logistic có thể được sử dụng như một công cụ hỗ trợ đánh giá và cảnh báo sớm rủi ro phá sản. Việc sử dụng xác suất phá sản thay vì các tiêu chí phân loại cứng giúp các chủ thể này linh hoạt hơn trong việc ra quyết định đầu tư và quản trị rủi ro.
Thứ ba, đối với cơ quan quản lý thị trường, kết quả nghiên cứu cho thấy, việc ứng dụng các mô hình định lượng dựa trên dữ liệu tài chính là cần thiết nhằm nâng cao hiệu quả giám sát và cảnh báo sớm các doanh nghiệp có dấu hiệu suy giảm tài chính, góp phần bảo đảm sự ổn định và phát triển bền vững của thị trường chứng khoán.
Tài liệu tham khảo:
1. Nguyễn Văn Công (2014). Phân tích báo cáo tài chính. H. NXB Tài chính.
2. Phan Thị Bích Nguyệt (2018). Dự báo nguy cơ phá sản của doanh nghiệp niêm yết tại Việt Nam bằng các chỉ tiêu tài chính. Tạp chí Phát triển Kinh tế, 29(4), tr. 45-58.
3. Trần Ngọc Thơ (2012). Tài chính doanh nghiệp hiện đại. TP. Hồ Chí Minh, NXB Thống kê.
4. Altman, E. I. (1968). Financial ratios, discriminant analysis and the prediction of corporate bankruptcy. The Journal of Finance, 23(4), 589-609. https://doi.org/10.2307/2978933
5. Chawla, N. V., Bowyer, K. W., Hall, L. O., & Kegelmeyer, W. P. (2002). SMOTE: Synthetic minority over-sampling technique. Journal of Artificial Intelligence Research, 16, 321-357. https://doi.org/10.1613/jair.953
6. He, H., & Garcia, E. A. (2009). Learning from imbalanced data. IEEE Transactions on Knowledge and Data Engineering, 21(9), 1263-1284. https://doi.org/10.1109/TKDE.2008.239
7. Fawcett, T. (2006). An introduction to ROC analysis. Pattern Recognition Letters, 27(8), 861–874. https://doi.org/10.1016/j.patrec.2005.10.010
8. Ohlson, J. A. (1980). Financial ratios and the probabilistic prediction of bankruptcy. Journal of Accounting Research, 18(1), 109-131. https://doi.org/10.2307/2490395
9. Shumway, T. (2001). Forecasting bankruptcy more accurately: A simple hazard model. The Journal of Business, 74(1), 101-124. https://doi.org/10.1086/209665.
10. Sun, J., Li, H., Huang, Q. H., & He, K. Y. (2014). Predicting financial distress and corporate failure: A review from definitions, modeling, sampling, and featuring approaches. Knowledge-Based Systems, 57, 41-56. https://doi.org/10.1016/j.knosys.2013.12.006.



