
Vietnamese stock price forecast: A Combination of market sentiment analysis and integrated machine learning modeling
PGS.TS. Nguyễn Thị Thu Thủy
Trần Văn Mạnh
Trần Thị Ly
Trường Đại học Thương mại
(Quanlynhanuoc.vn) – Trong bối cảnh thị trường chứng khoán Việt Nam ngày càng chịu tác động mạnh từ dòng thông tin và tâm lý nhà đầu tư, việc nâng cao độ chính xác của các mô hình dự báo giá cổ phiếu trở thành yêu cầu cấp thiết. Vì vậy, bài viết tập trung nghiên cứu sự kết hợp giữa phân tích tâm lý thị trường và mô hình học máy tích hợp, nhằm dự báo xu hướng biến động giá cổ phiếu tại Việt Nam. Trên cơ sở khai thác dữ liệu giao dịch cùng các nguồn tin tức tài chính, nghiên cứu đánh giá mức độ ảnh hưởng của thông tin thị trường đến hành vi nhà đầu tư và hiệu quả dự báo của mô hình. Kết quả nghiên cứu góp phần khuyến nghị một hướng tiếp cận mới trong phân tích và dự báo thị trường chứng khoán, hỗ trợ nhà đầu tư đưa ra quyết định chính xác và hiệu quả trong đầu tư.
Từ khóa: Dự báo, giá cổ phiếu, phân tích tâm lý, mô hình học máy tích hợp.
Abstract: In the context of the Vietnamese stock market being increasingly influenced by information flows and investor sentiment, improving the accuracy of stock price forecasting models has become an urgent requirement. Therefore, this article focuses on researching the combination of market sentiment analysis and integrated machine learning models to forecast stock price trends in Vietnam. Based on the exploitation of trading data and financial news sources, the study evaluates the extent to which market information affects investor behavior and the model’s forecasting effectiveness. The research results inform the recommendation of a new approach to stock market analysis and forecasting, supporting investors in making accurate and effective investment decisions.
Keywords: Forecasting, stock price, sentiment analysis, integrated machine learning model.
1. Đặt vấn đề
Thị trường chứng khoán đóng vai trò quan trọng trong hệ thống tài chính của mỗi quốc gia, là kênh huy động vốn hiệu quả cho doanh nghiệp và là công cụ đầu tư phổ biến của nhà đầu tư. Tuy nhiên, biến động giá cổ phiếu chịu tác động đồng thời từ nhiều yếu tố khác nhau, bao gồm: yếu tố nội tại của doanh nghiệp, diễn biến thị trường và các chỉ báo kỹ thuật cũng như thông tin, tin tức và tâm lý nhà đầu tư. Điều này khiến việc dự đoán xu hướng giá cổ phiếu trở thành bài toán phức tạp và đầy thách thức.
Trong những năm gần đây, cùng với sự phát triển mạnh mẽ của trí tuệ nhân tạo (AI) và khoa học dữ liệu, các mô hình học máy (Machine learning) và học sâu (Deep learning) ngày càng được ứng dụng rộng rãi trong lĩnh vực tài chính – chứng khoán. Đặc biệt, các mô hình mạng nơ-ron, như Long short-term Memory (LSTM) và mạng nơ-ron tích chập (Convolutional Neural Network – CNN), đã chứng minh khả năng xử lý dữ liệu chuỗi thời gian và trích xuất đặc trưng hiệu quả, góp phần nâng cao độ chính xác trong dự báo giá cổ phiếu so với các phương pháp thống kê truyền thống. Bên cạnh các dữ liệu định lượng như giá cổ phiếu lịch sử, báo cáo tài chính và các chỉ báo kỹ thuật, nhiều nghiên cứu gần đây cho thấy thông tin định tính từ tin tức tài chính, báo chí và các báo cáo phân tích doanh nghiệp cũng ảnh hưởng đáng kể đến biến động giá cổ phiếu. Tuy nhiên, việc khai thác và lượng hóa yếu tố cảm xúc (sentiment) từ các nguồn dữ liệu văn bản tiếng Việt vẫn còn nhiều hạn chế và chưa được nghiên cứu đầy đủ.
Xuất phát từ thực tiễn đó, nghiên cứu về việc kết hợp giữa việc phân tích tâm lý thị trường với các kỹ thuật của mô hình học máy tích hợp và cụ thể là học sâu được lựa chọn. Nghiên cứu xây dựng các mô hình này để dự báo giá cổ phiếu dựa trên nhiều nguồn dữ liệu khác, như dữ liệu lịch sử giá, báo cáo tài chính, các chỉ báo kỹ thuật và dữ liệu tin tức tài chính. Các kết quả thực nghiệm chỉ ra sự cải thiện rõ ràng của các mô hình học sâu như LSTM, CNN và mô hình lai CNN-LSTM. Điều này khẳng định vai trò của yếu tố tâm lý cảm xúc quan trọng trong việc cải thiện chất lượng dự báo cổ phiếu, giúp cho các nhà đầu tư có cơ sở trong việc đầu tư trên sàn chứng khoán.
2. Tổng quan nghiên cứu về dự báo cổ phiếu sử dụng học máy
Trong bối cảnh diễn biến phức tạp của nền kinh tế toàn cầu, thị trường chứng khoán nước ta đã thể hiện khả năng phục hồi và tiềm năng tăng trưởng dài hạn. Hiệu suất của thị trường chứng khoán có mối tương quan với các xu hướng kinh tế và chính trị toàn cầu. Do đó, dự báo giá cổ phiếu ngày càng thu hút sự chú ý. Tuy nhiên, theo xu hướng chung, thị trường này vẫn phải đối mặt với nhiều thách thức do sự biến động của thị trường. Thông thường, biến động giá cổ phiếu bị ảnh hưởng bởi các yếu tố như báo cáo lợi nhuận, tin tức và hành vi của nhà đầu tư. Trên các sàn giao dịch chứng khoán, các nhà giao dịch sử dụng các chỉ báo kỹ thuật, nhưng việc dự đoán chính xác các xu hướng hàng ngày và hàng tuần vẫn còn là một thách thức (Ticknor, 2013)1. Các nhà đầu tư thường tìm kiếm khả năng dự báo và phân tích các yếu tố tâm lý, điều kiện tài chính, các quy định về chính sách và động lực thị trường. Tuy nhiên, dữ liệu về giá cổ phiếu thường có tính biến động cao, phi tham số và phi tuyến tính, điều này khiến việc dự đoán xu hướng của giá trở nên khó khăn. Do đó, việc dự báo chuỗi thời gian (đơn cử như dự đoán giá cổ phiếu ở nghiên cứu này) sẽ phải đối mặt với nhiều thách thức, như sự biến động của giá và tính bất thường, các yếu tố nhiễu… Ngoài ra, các tác động tâm lý và hành vi của nhà đầu tư cũng đóng vai trò thiết yếu trong việc định hình xu hướng thị trường tài chính, đặc biệt là ở các thị trường mới nổi như Việt Nam.
Trong những thập kỷ qua, các nghiên cứu đã liên tục nhấn mạnh tầm quan trọng của tâm lý nhà đầu tư trong việc giải thích sự biến động giá cổ phiếu. Đơn cử, Shiller (2003)2 lập luận rằng sự tăng giá cổ phiếu được thúc đẩy bởi tâm lý của người mua. Tương tự, Lee và cộng sự (2002)3 đã xác định mối liên hệ giữa sự thay đổi tâm lý nhà đầu tư và sự biến động của thị trường. Đồng thời, nghiên cứu thực nghiệm của Lucey và Dowling (2005)4 cũng chỉ ra rằng các chỉ số tâm lý nhà đầu tư có mối tương quan mạnh mẽ với lợi nhuận thị trường. Xuất phát từ những nhu cầu này, nhiều mô hình khác nhau đã được sử dụng để dự báo giá cổ phiếu, đơn cử như mô hình Chuỗi thời gian (Autoregressive Conditional Heteroskedasticity – ARCH), mô hình Tự hồi quy tổng quát (Generalized Autoregressive Conditional Heteroskedasticity – GARCH) và mô hình Tự hồi quy tích hợp trung bình trượt (Autoregressive Integrated Moving Average – ARIMA). Ý tưởng chính của các mô hình này là khai thác các mối liên hệ tuyến tính trong dữ liệu lịch sử để đưa ra dự báo ngắn hạn. Tuy nhiên, những phương pháp này thường dựa trên giả định về tính tuyến tính và phương sai không đổi, điều này rất ít khi xảy ra trong các thị trường tài chính đầy biến động (Singh và Singh, 2024)5. Do đó, độ chính xác của các mô hình thống kê thường thấp hơn đáng kể so với các kỹ thuật học máy hiện đại (Trần Phúc và cộng sự, 2024)6.
Đặc biệt, mạng thần kinh tái hồi (RNN) và biến thể LSTM đã tạo ra bước ngoặt trong việc mô hình hóa chuỗi thời gian nhờ cơ chế cổng kiểm soát thông tin (Lu và cộng sự, 2020)7. Ý tưởng chính của LSTM là sử dụng trạng thái ô (cell state) để duy trì bộ nhớ dài hạn, giúp giải quyết triệt để vấn đề mất mát tín hiệu (vanishing gradient) của RNN truyền thống (Tran Phuoc và cộng sự, 2024)8. Đồng thời, nhiều nghiên cứu xác nhận rằng LSTM đơn lẻ vẫn vượt trội hơn các mô hình học máy cơ bản về độ chính xác dự báo (Zhang và cộng sự, 2024)9.
Bên cạnh LSTM, CNN cũng được chuyển đổi từ lĩnh vực xử lý hình ảnh sang dự báo tài chính để trích xuất các đặc trưng không gian cục bộ (Singh và Singh, 2024)10. Tuy nhiên, hạn chế cốt lõi của CNN là thiếu cơ chế lưu trữ bộ nhớ dài hạn, dẫn đến việc bỏ sót các xu hướng chu kỳ kéo dài (Zhao, 2024)11. Đặc biệt, một số nghiên cứu cho thấy CNN đặc biệt hiệu quả cho các dự báo cực ngắn hạn nhưng kém ổn định hơn LSTM trong các kịch bản trung hạn (Giang và cộng sự, 2025)12. Vì vậy, xu hướng nghiên cứu hiện đại đã chuyển dịch mạnh mẽ sang các mô hình lai CNN-LSTM, nhằm kết hợp sức mạnh của cả hai kiến trúc. Ý tưởng chủ đạo là sử dụng các lớp CNN để trích xuất đặc trưng cục bộ và giảm nhiễu trước khi đưa vào các lớp LSTM để học các phụ thuộc thời gian dài hạn (Lan, 2025)13. Dữ liệu được sử dụng thường là các bộ chỉ số đa chiều kết hợp với nhiều chỉ báo kỹ thuật phức tạp (Dong và Liang, 2025)14. Ưu điểm của cách tiếp cận này là cải thiện đáng kể độ chính xác và tính ổn định so với việc sử dụng các mô hình đơn lẻ. Các bài báo thực nghiệm đã chứng minh rằng mô hình lai CNN-LSTM đạt được chỉ số sai số như: Sai số căn phương trung bình (Root Mean Square Error – RMSE), Sai số tuyệt đối trung bình (Mean Absolute Error – MAE) thấp hơn và Hệ số xác định (R-squared – R2) cao hơn trong hầu hết các kịch bản thử nghiệm (Bhanujyothi và Jacob, 2025)15.
Vì vậy, xu hướng hiện nay là chuyển từ các mô hình đơn mục tiêu sang các mô hình đa mục tiêu, kết hợp cả dự báo giá và đánh giá rủi ro. Mặc dù vậy, tính “hộp đen” của các mô hình học sâu vẫn là một thách thức lớn đối với sự tin tưởng của các nhà đầu tư chuyên nghiệp (Lan, 2025)16. Các nghiên cứu tương lai được kỳ vọng sẽ tập trung vào việc cải thiện khả năng giải thích và thích ứng linh hoạt với các thay đổi đột ngột của thị trường (Bhanujyothi và Jacob, 2025)17.
3. Phương pháp nghiên cứu
Nghiên cứu sử dụng phương pháp nghiên cứu định lượng và thực nghiệm, cụ thể như sau:
Phương pháp thu thập và xử lý dữ liệu: kỹ thuật thu thập dữ liệu tự động từ website được thực hiện thông qua một chương trình nhỏ với ngôn ngữ lập trình Python để thu thập dữ liệu giá cổ phiếu, báo cáo tài chính, tin tức và báo cáo phân tích doanh nghiệp. Sau đó, dữ liệu được làm sạch, chuẩn hóa để chuẩn bị cho quy trình thực nghiệm.
Phương pháp phân tích sentiment: nghiên cứu áp dụng mô hình ngôn ngữ lớn thông qua nền tảng NotebookLM để đánh giá cảm xúc của tin tức và báo cáo phân tích. Các kết quả của cảm xúc sau đó được lượng hóa thành chỉ số số học theo ngày giao dịch thông qua việc đánh giá điểm trung bình cảm xúc của ngày giao dịch.
Phương pháp mô hình hóa: nghiên cứu xây dựng và huấn luyện các mô hình học sâu với các kỹ thuật LSTM, CNN và CNN-LSTM trên bộ dữ liệu đã chuẩn hóa.
Phương pháp đánh giá: nghiên cứu sử dụng các chỉ tiêu đánh giá sai số và mức độ phù hợp của mô hình để so sánh hiệu quả dự báo của các mô hình với các công thức:
MAE được dùng để đo lường mức độ sai lệch trung bình tuyệt đối giữa giá trị dự báo và giá trị thực tế.
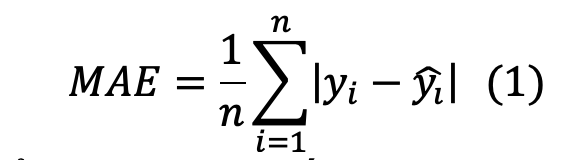
MAPE được dùng để đo lường sai số trung bình tuyệt đối dưới dạng tỷ lệ phần trăm so với giá trị thực tế, giúp so sánh hiệu quả mô hình trên các thang đo khác nhau.
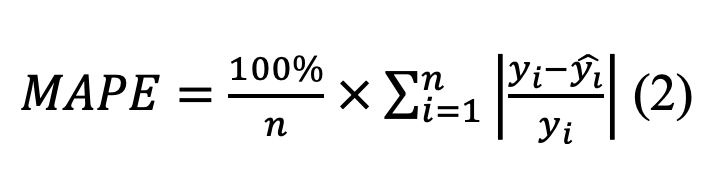
Hệ số xác định là chỉ số đánh giá mức độ phù hợp của mô hình hồi quy, phản ánh tỷ lệ phương sai của biến phụ thuộc (thực tế) được mô hình giải thích.
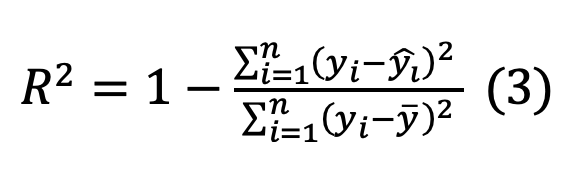
Trong các công thức trên, giá trị càng cao thì mô hình dự báo càng giải thích được phần lớn biến thiên của dữ liệu; ngược lại, giá trị thấp thì mô hình chưa khai thác hết mối quan hệ giữa biến độc lập và biến phụ thuộc. Đây là chỉ số chuẩn để so sánh mức độ phù hợp giữa các mô hình hồi quy tuyến tính khác nhau.
4. Kết quả thực nghiệm
Thứ nhất, về dữ liệu thực nghiệm.
Nghiên cứu thu thập dữ liệu về lịch sử giá cổ phiếu từ năm 2018 đến tháng 3/2025 và các bài báo liên quan đến các doanh nghiệp cũng được thu thập từ nền tảng thông tin tài chính uy tín CafeF.vn. Để bảo đảm dữ liệu thu thập được toàn diện, chính xác và đa chiều, nhóm tác giả đã áp dụng phương pháp thu thập kép dựa trên từ khóa và thu thập dựa trên danh mục từ mục “Tin tức – Sự kiện” của mỗi công ty. Phương pháp này có ưu điểm là phạm vi bao phủ rộng, không chỉ tin tức chính thức mà còn cả các bài báo phân tích, đánh giá, bình luận cũng như tin tức thị trường liên quan đến doanh nghiệp, ngay cả khi chúng không được phân loại trong các mục tin tức chính của công ty. Điều này cho thấy nhóm tác giả nắm bắt nhiều góc nhìn về doanh nghiệp và các yếu tố ảnh hưởng bên ngoài. Việc kết hợp hai phương pháp thu thập trên là cần thiết để cân bằng điểm mạnh và điểm yếu của chúng dựa trên danh mục bảo đảm tính chính xác, nguồn chính thức và nội dung có cấu trúc. Sau khi thu thập dữ liệu từ hai nguồn, dữ liệu được hợp nhất, chuẩn hóa và loại bỏ trùng lặp, tạo một tập dữ liệu hoàn chỉnh, sạch sẽ và có giá trị cao để phân tích và trích xuất thông tin tiếp theo. Các tập dữ liệu từ hai nguồn được hợp nhất thành một tập dữ liệu duy nhất bằng cách sử dụng thư viện Python để tạo thành một khung dữ liệu thống nhất.
Trong quá trình xử lý, các bản ghi không hợp lệ, chẳng hạn như những bản ghi thiếu ngày xuất bản hoặc thiếu nội dung bài báo, có thể được trích xuất và bị loại bỏ để bảo đảm chất lượng của tập dữ liệu cuối cùng. Ngoài ra, các bài báo trùng lặp có cùng tiêu đề (có thể xuất hiện đồng thời ở cả hai nguồn dữ liệu) được tự động lọc bỏ, chỉ giữ lại bản ghi có thời gian xuất bản mới nhất nhằm bảo đảm tính cập nhật và hạn chế dư thừa dữ liệu. Nội dung bài báo sau đó tiếp tục được xử lý để loại bỏ các thông tin lặp lại, không cần thiết hoặc gây nhiễu trong phần tóm tắt ban đầu, qua đó bảo đảm nội dung ngắn gọn, mạch lạc và tập trung vào những thông tin cốt lõi liên quan đến doanh nghiệp.
Thứ hai, về cấu hình thực nghiệm.
Nhóm tác giả tiến hành thí nghiệm với ba mô hình học sâu là CNN, LSTM và mô hình lai LSTM-CNN trên máy tính cá nhân với cấu hình sau:
Bộ xử lý Intel® (R) Core (TM) i5-1235U 1.30 GHz, RAM 8 GB và sử dụng ngôn ngữ lập trình Python trên hệ điều hành Windows 11. Quá trình xây dựng, huấn luyện và đánh giá mô hình được thực hiện trên nền tảng Google Colab sử dụng GPU T4. Dữ liệu thí nghiệm được áp dụng cho ba mã chứng khoán: VNM, FPT và HPG.
Thứ ba, về kết quả thực nghiệm.
Dữ liệu thực nghiệm sẽ được thu thập theo hai kịch bản: thực nghiệm với các mô hình khi không tích hợp việc phân tích cảm xúc và khi tích hợp các mức độ cảm xúc. Kết quả thực nghiệm được trình bày chi tiết trong Bảng 1 (khi không tích hợp các mức độ cảm xúc) và Bảng 2 (khi tích hợp các mức độ cảm xúc).
Bảng 1: Kết quả thực nghiệm khi không tích hợp các phân tích cảm xúc
| Stock Code | Model | R2 Test | MAE (VNĐ) | MAPE (%) |
| VNM | LSTM | 0.8936 | 0.97 | 1,45 |
| VNM | CNN | 0.3806 | 2.40 | 3,64 |
| VNM | CNN-LSTM | 0.7725 | 1.3590 | 2,04 |
| FPT | LSTM | 0.8137 | 5.71 | 4,26 |
| FPT | CNN | 0.7862 | 5.51 | 4,27 |
| FPT | CNN-LSTM | 0.9645 | 2.6104 | 2,04 |
| HPG | LSTM | -0.0804 | 1.33 | 4,75 |
| HPG | CNN | -0.0317 | 0.61 | 2,29 |
| HPG | CNN-LSTM | 0.8531 | 0.4560 | 1,66 |
Bảng 2: Kết quả thực nghiệm với việc tích hợp phân tích cảm xúc
| Stock Code | Model | R2 Test | MAE (VNĐ) | MAPE (%) |
| VNM | LSTM | 0.8032 | 1.35 | 2,04 |
| VNM | CNN | 0.6791 | 1.60 | 2,34 |
| VNM | CNN-LSTM | 0.7409 | 1.3863 | 2,05 |
| FPT | LSTM | 0.2550 | 12.00 | 8,99 |
| FPT | CNN | 0.7029 | 6.59 | 5,07 |
| FPT | CNN-LSTM | 0.9461 | 3.2660 | 2,45 |
| HPG | LSTM | 0.0118 | 1.16 | 4,12 |
| HPG | CNN | 0.8001 | 3.70 | 10,18 |
| HPG | CNN-LSTM | 0.8536 | 0.4576 | 1,65 |
Để nghiên cứu chi tiết về việc dự báo của các mô hình, nhóm tác giả đã sử dụng mô hình lai kết hợp của CNN và LSTM để so sánh giá cổ phiếu thực với giá dự báo. Kết quả được thể hiện ở Biểu đồ 1, 2 và 3 dưới đây.
Biểu đồ 1: Kết quả thực nghiệm của mô hình lai CNN-LSTM kết hợp sử dụng phân tích cảm xúc cho cổ phiếu VNM
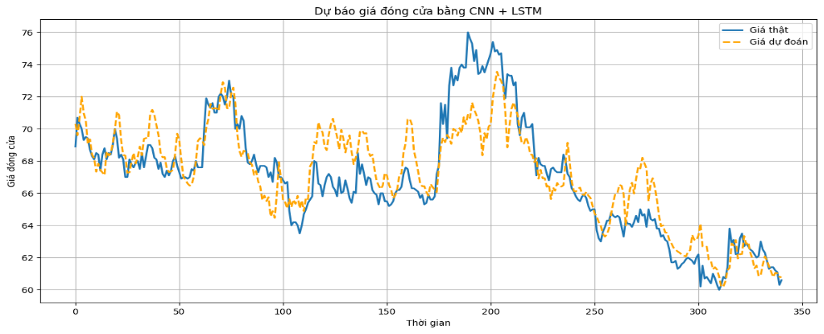
Biểu đồ 2: Kết quả thực nghiệm của mô hình lai CNN – LSTM kết hợp sử dụng phân tích cảm xúc cho cổ phiếu FPT
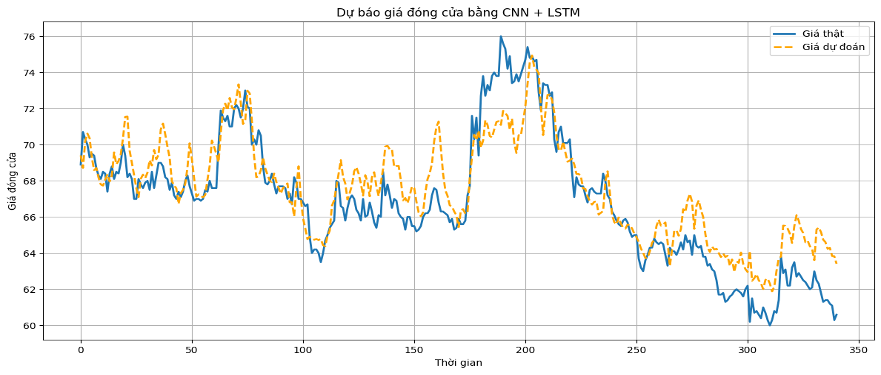
Biểu đồ 3: Kết quả thực nghiệm của mô hình lai CNN-LSTM kết hợp sử dụng phân tích cảm xúc cho cổ phiếu HPG
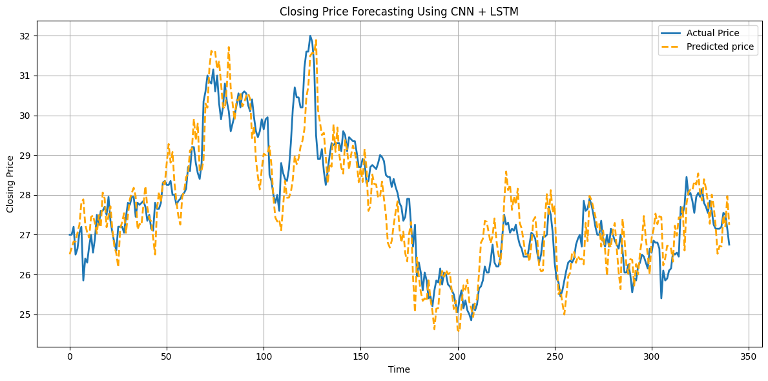
5. Kết quả thảo luận
Kết quả thực nghiệm cho thấy sự biến động rõ rệt trong hiệu suất của các mô hình học sâu khi có và không có sự tham gia của dữ liệu phân tích cảm xúc đối với ba mã cổ phiếu VNM, FPT và HPG.
Tại Bảng 1, khi chưa tích hợp phân tích cảm xúc, mô hình CNN-LSTM thể hiện ưu thế vượt trội về khả năng dự báo, đặc biệt đối với mã FPT với hệ số R2 đạt mức ấn tượng là 0,9645 và mã HPG đạt 0,8531. Điều này có nghĩa là với mô hình lai CNN-LSTM, dự báo giá cổ phiếu của FPT và HPG phụ thuộc vào các yếu tố như lịch sử giá, dữ liệu từ báo cáo tài chính. Đồng thời, các mô hình đơn lẻ CNN lại bộc lộ hạn chế lớn với chỉ số R2 thấp, thậm chí âm ở mã HPG (-0,0317). Điều này cho thấy, cấu trúc tích chập thuần túy của mô hình học sâu CNN khó có thể nắm bắt được tính chất chuỗi thời gian phức tạp của dữ liệu chứng khoán nếu thiếu sự hỗ trợ từ các lớp học của mô hình. Tuy nhiên, đối với mã VNM, mô hình LSTM đơn lẻ lại đạt kết quả tốt nhất (R2 = 0,8936) so với cấu trúc kết hợp, gợi ý rằng đặc điểm dữ liệu của mã này có thể ít bị nhiễu hơn và phù hợp với cơ chế ghi nhớ dài hạn của LSTM.
Tại Bảng 2 (khi dữ liệu cảm xúc được tích hợp vào mô hình), một hiện tượng đáng chú ý đã xảy ra, đó là sự sụt giảm hiệu suất ở các mã vốn đã có kết quả tốt trước đó. Ví dụ, đối với VNM và FPT, hầu hết các chỉ số R2 đều giảm và sai số (MAE, MAPE) có xu hướng tăng lên sau khi thêm biến cảm xúc. Điển hình là mô hình LSTM của FPT chứng kiến sự sụt giảm nghiêm trọng về R2 từ 0,8137 xuống còn 0,2550. Điều này có thể được lý giải bởi sự “nhiễu” từ dữ liệu cảm xúc hoặc sự không tương quan trực tiếp giữa tâm lý đám đông và biến động giá thực tế của các mã blue-chip này trong giai đoạn nghiên cứu. Ngược lại, mã HPG lại cho thấy được sự cải thiện đáng kể ở mô hình CNN và LSTM sau khi tích hợp cảm xúc. Mô hình từ mức R2 âm ở Bảng 1, mô hình CNN của HPG đã nhảy vọt lên 0,8001 ở Bảng 2. Kết quả này chứng minh rằng đối với một số loại cổ phiếu có tính đầu cơ hoặc nhạy cảm với tin tức thị trường cao như HPG, thông tin cảm xúc đóng vai trò là một biến số bổ trợ quan trọng giúp mô hình nhận diện xu hướng tốt hơn.
Nhìn vào Biểu đồ 1, 2, 3, có thể nhận định rằng mô hình lai CNN-LSTM vẫn duy trì được sự ổn định cao nhất trên cả hai bảng dữ liệu, khẳng định đây là cấu trúc tối ưu để xử lý các nguồn dữ liệu đa dạng trong bài toán dự báo tài chính. Các đồ thị biểu diễn kết quả dự báo cho thấy mô hình CNN-LSTM có khả năng bám sát xu hướng biến động chung của giá đóng cửa thực tế trên cả ba mã cổ phiếu VNM, FPT và HPG. Khi quan sát Biểu đồ 1 và 2, có thể thấy đường giá dự đoán (đường đứt đoạn màu vàng) phản ánh khá nhạy bén các nhịp tăng giảm của giá thật (đường liền nét màu xanh). Tuy nhiên, tại các điểm cực trị của những vùng giá cao nhất hoặc thấp nhất đột ngột vẫn có độ trễ nhất định và đôi khi chưa dự báo sát được biên độ biến động mạnh nhất. Điều này có thể hàm ý rằng dữ liệu tài chính của các mô hình đang có độ nhiễu cao.
Đối với cổ phiếu HPG tại Biểu đồ 3, mô hình thể hiện sự ổn định đáng kể trong việc theo dõi các chu kỳ biến động ngắn hạn. Sự tương đồng giữa đường giá dự báo và giá thực tế ở mã này củng cố thêm nhận định rằng việc kết hợp phân tích cảm xúc giúp mô hình “hiểu” tốt hơn các phản ứng của thị trường đối với mã cổ phiếu này. Mặc dù có những khoảng cách nhỏ giữa giá trị dự báo và thực tế ở một số giai đoạn giữa chu kỳ, nhưng về tổng thể, mô hình lai CNN-LSTM đã chứng minh được hiệu quả trong việc nắm bắt các điểm đảo chiều quan trọng. Chính vì vậy, việc duy trì được quỹ đạo dự báo sát với thực tế trong một khoảng thời gian dài cho thấy tính bền vững của cấu trúc CNN-LSTM khi xử lý đa nguồn dữ liệu.
6. Kết luận
Nghiên cứu đã đánh giá khả năng dự báo giá đóng cửa cổ phiếu của các mô hình học sâu gồm LSTM, CNN và CNN-LSTM khi kết hợp với phân tích cảm xúc thị trường đối với ba mã cổ phiếu VNM, FPT và HPG. Kết quả thực nghiệm cho thấy mô hình lai CNN-LSTM đạt hiệu quả dự báo tốt nhất với hệ số xác định R² cao cùng các chỉ số sai số MAE và MAPE thấp, thể hiện tính ổn định và khả năng thích ứng vượt trội so với các mô hình đơn lẻ trong điều kiện dữ liệu có độ biến động lớn.
Kết quả nghiên cứu đồng thời cho thấy tác động của dữ liệu cảm xúc thị trường đến hiệu quả dự báo không đồng nhất giữa các mã cổ phiếu. Việc tích hợp chỉ số cảm xúc giúp cải thiện đáng kể độ chính xác dự báo đối với VNM và HPG nhờ khả năng phản ánh tốt hơn tâm lý nhà đầu tư. Ngược lại với mã FPT, các biến cảm xúc tạo ra nhiễu và làm suy giảm hiệu suất mô hình. Bên cạnh đó, mô hình LSTM hoạt động hiệu quả trong điều kiện không sử dụng dữ liệu cảm xúc nhưng giảm đáng kể độ chính xác khi bổ sung các biến sentiment, trong khi mô hình CNN thuần túy cho thấy hạn chế đối với các tập dữ liệu có độ nhiễu cao và chỉ phù hợp với những cổ phiếu có biến động tương đối ổn định.
Trên cơ sở đó, nghiên cứu gợi mở hướng phát triển các mô hình dự báo chứng khoán theo hướng tích hợp đa nguồn dữ liệu và cải tiến kiến trúc học sâu. Trong tương lai, cần mở rộng dữ liệu đầu vào từ báo điện tử, diễn đàn chứng khoán và các kênh thông tin chính thức của doanh nghiệp nhằm nâng cao chất lượng chỉ số cảm xúc thị trường. Đồng thời, việc ứng dụng các cơ chế Attention hoặc kiến trúc Transformer có thể giúp mô hình tập trung tốt hơn vào các yếu tố quan trọng trong chuỗi thời gian. Ngoài ra, các nghiên cứu tiếp theo cần kiểm định mô hình trong những bối cảnh thị trường đặc biệt như khủng hoảng kinh tế, suy thoái hoặc biến động chính trị mạnh nhằm đánh giá khả năng thích ứng và nâng cao độ tin cậy của các dự báo tài chính.
Chú thích:
1. Ticknor, J. (2013). A Bayesian regularized artificial neural network for stock market forecasting. Expert Systems with Applications. Vol. 40, 14, Pp 5501-5506. https://doi.org/10.1016/j.eswa.2013.04.013.
2. Shiller, R. J. (2003). From Efficient Markets Theory to Behavioral Finance. Journal of Economic Perspectives. Vol 17, 1, Pp 83-104. DOI: 10.1257/089533003321164967
3. Lee, W. Y., Jiang, C. X. & Indro, D. C. (2002). Stock market volatility, excess returns, and the role of investor sentiment. Journal of Banking & Finance, Elsevier, vol. 26(12), Pp 2277-2299.
4. Lucey, B. M., & Dowling, M. (2005). The Role of Feelings in Investor Decision-Making. Journal of Economic Surveys, 19(2), 211-237. https://doi.org/10.1111/j.0950-0804.2005.00245.x
5, 10. Singh, J., & Singh, G. (2024). Deep learning for financial forecasting. Journal of Management World. https://doi.org/10.53935/jomw.v2024i4.1070.
6, 8. Tran Phuoc, Pham Thi Kim Anh, Phan Huy Tam, & Chien V. Nguyen. (2024). Applying machine learning algorithms to predict the stock price trend in Vietnam. Humanities & Social Sciences Communications. https://doi.org/10.1057/s41599-024-02807-x
9. Zhang, J., Chan, W., & Lin, Y. (2024). Stock price prediction research based on CNN-LSTM. Highlights in Business. Economics and Management, 41, 789–829. https://doi.org/10.54097/cyqrxb84.
11. Zhao, X. (2024). Exploring the performance of the CNN-LSTM model in stock prediction. Highlights in Business, Economics and Management, 45, 509–534. DOI: https://doi.org/10.54097/x9m1cm10
12. Giang, N. T. H., Thanh, L. M., & Nguyen-Dinh, C. H. (2025). A novel compact 1D-CNN architecture for short-term stock price prediction. International Journal of Innovative Computing, Information and Control, 21(5), 1401–1414.
13, 16. Lan, Y. (2025). A hybrid CNN-LSTM model for stock price prediction with spatial and temporal dependencies. Proceedings of CONF-FMCE 2025 Symposium. https://doi.org/10.54254/2755-2721/155/2025.GL23570
14. Dong, J., & Liang, S. (2025). Hybrid CNN-LSTM-GNN neural network for A-share stock prediction. Entropy, 27(881). https://doi.org/10.3390/e27080881
15, 17. Bhanujyothi, H. C., & Jacob, I. J. (2025). A hybrid CNN-LSTM attention-based deep learning model for stock price prediction using technical indicators. Engineering, Technology & Applied Science Research, 15(5), 28012–28017.
Tài liệu tham khảo:
1. Đỗ Hồng Nhung, Hoàng Nhật Khánh, Phạm Hoàng Vũ, Nguyễn Thị Duy Linh, Bùi Thị Thúy Nga, Đặng Chí Bách. Áp dụng mô hình dự báo deep learning trên thị trường chứng khoán Việt Nam: thực trạng và giải pháp. DOI: http://doi.org/10.57001/huih5804.2025.216
2. Dự báo chỉ số chứng khoán bằng học máy: Bằng chứng thực nghiệm từ thị trường chứng khoán Việt Nam. https://kinhtevadubao.vn/du-bao-chi-so-chung-khoan-bang-hoc-may-bang-chung-thuc-nghiem-tu-thi-truong-chung-khoan-viet-nam-29030.html



